

How Good Is Google PaLM at Translation?
How Good Is Google PaLM at Translation?
Not that good, but we are getting there


Since the release of GPT-3, several other large language models have been introduced and evaluated in machine translation.
But how good are large language models at translation compared to the standard machine translation encoder-decoder approach?
Unfortunately, we can’t easily answer this question.
The evaluations of large language models for translation are often too sloppy or incomplete to draw credible conclusions.
To have a clear answer, a research team from Google proposed the first extensive evaluation comparing a large language model with state-of-the-art machine translation systems.
This work has been publicly released on arXiv (November 28th) and is proposed by David Vilar, Markus Freitag, Colin Cherry, Jiaming Luo, Viresh Ratnakar, and George Foster.
In this blog article, I review their work, share my comments, and summarize their findings. I also pinpoint the main reasons why I think the evaluation conducted in this work is outstanding and calls for better evaluation of language models.
Context
GPT-3, FLAN, and more recently PaLM, among others, are language models that all demonstrated an impressive ability to perform translation.
GPT-3 and PALM even claim to achieve a translation quality on par with some standard machine translation systems.
However, these claims were solely based on improvements measured with BLEU, the standard automatic evaluation metric for machine translation. BLEU is well known to poorly correlate with human judgments.

An evaluation with better automatic metrics and/or a manual evaluation is needed to confirm that language models and standard machine translation systems achieve a similar translation quality.
A good evaluation of large language models should also fully report on how the prompts were designed and selected.
What’s a prompt?
Let’s define that a prompt is the text given as input to a language model. It can contain a description of the task we want the model to do and/or examples of the task, for instance, translations.
In PaLM and GPT-3 papers, the prompts used for the machine translation experiments, and the selection strategy of the translation examples used for few-shot prompting, are not disclosed although it is well-known that the performance of these models can dramatically vary depending on the prompts.
What’s few-shot prompting?
Large language models are usually not trained for a specific task. Thanks to pre-training, we can teach them a task by simply including a few examples of the task. For instance, in this work PaLM is prompted with 5 translation examples.
In their work, Vilar et al. first evaluate different strategies to make and select prompts.
They choose the most promising ones and then evaluate the translation quality of the language model PaLM and standard machine translation systems using BLEURT as an automatic evaluation metric and the MQM framework (Lommel et al., 2014) for manual evaluation.
What’s BLEURT?
The repository of BLEURT gives the following definition: “BLEURT is an evaluation metric for Natural Language Generation. It takes a pair of sentences as input, a reference and a candidate, and it returns a score that indicates to what extent the candidate is fluent and conveys the meaning of the reference.”
It is a state-of-the-art neural metric that better correlates with human judgment than BLEU for machine translation evaluation.
Prompts For Machine Translation
They use the following prompt design:
[source]: X₁
[target]: Y₁
...
[source]: Xₙ
[target]: Yₙ
[source]: X
[target]:Where [source] and [target] are the language names in English, Xₙ some examples of sentences in the [source] language to translate, Yₙ their corresponding translations in the [target] language, and X is the current sentence that we want to translate. With the last line, “[target]:”, we expect the language model to generate the translation of X.
Vilar et al. make the assumption that the design of the prompts is “unimportant” for few-shot prompting. They don’t cite any previous work to back up this assumption. It probably comes from their observations in preliminary experiments, even though I believe it strongly depends on the language model used.
Assuming that the prompt design is not important also helps to make the paper more concise to focus on more critical aspects, such as the selection of the translation examples for few-shot prompting.
The source of these examples is translation datasets that I will denote pool in the remainder of this article.
They explored different strategies to select the examples from a given pool:
random selection
k-nearest neighbor (kNN) search
The kNN search retrieves from a pool the k examples of sentences, and their corresponding translations, that are the closest to the sentence we want to translate.
To measure how close the sentences are, they used two different models to embed the sentences:
Bag-of-words (BOW)
RoBERTa
They kept the kNN search very efficient by using ScaNN.
In their evaluation, they found that kNN with RoBERTa retrieved more useful examples than with BOW.
Note: I won’t further detail this aspect of their work to keep this article brief.
Prompt Pool

Translation examples are selected from 3 different types of pools:
A large dataset of millions of translations mixing multiple domains and styles denoted WMT full.
A small dataset of a few thousand translations in the same domain and style as the data we want to translate is denoted WMT dev.
A tiny dataset containing less than 200 translations of paragraphs, manually selected, but in a domain and style that may mismatch the ones of the data to translate, denoted high-end.
Based on empirical experiments using these 3 pools, the authors found that choosing high-quality translations is the most important. Choosing examples from the high-end pool yields results close to choosing the examples from the WMT dev pool despite the style and domain mismatches.
An Outstanding Evaluation

They mainly conducted their evaluation with the language pairs German-English and Chinese-English using the evaluation datasets released by WMT21.
They also show results for English-French, but using much older evaluation datasets that may have been included in the training data of the evaluated machine translation systems. The authors openly comment on this issue and provide the results for this dataset only to follow the original evaluation setup proposed in the PaLM paper. They don’t draw any definitive conclusions from the English-French results.
Let’s have a look at how they present their main results:
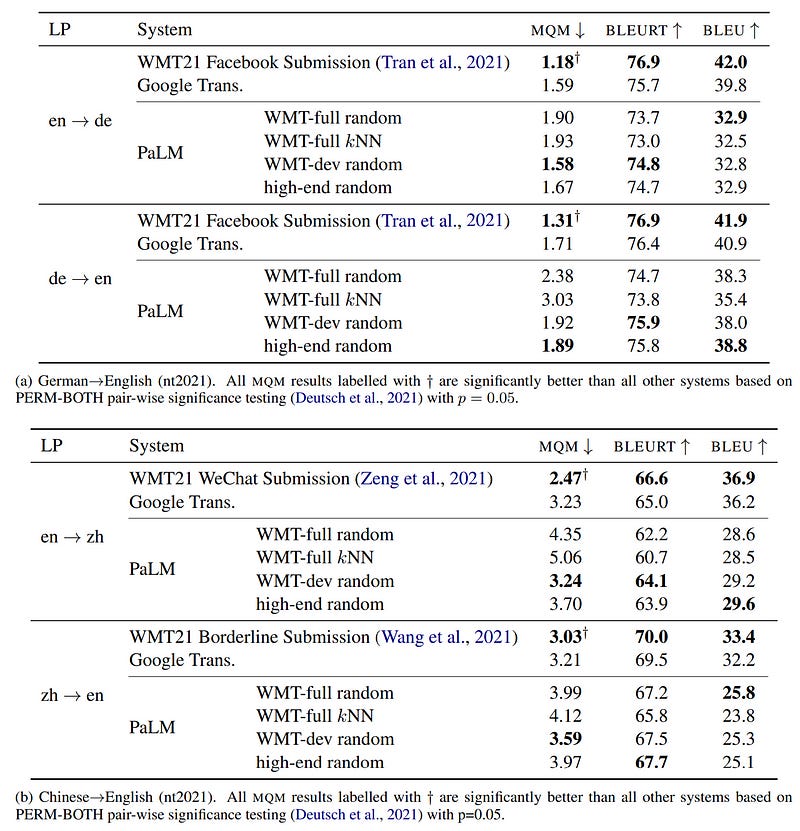
That’s a lot of numbers!
But I think they are all needed, and relevant, to draw conclusions from the experiments.
As we discussed earlier, they report on manual and automatic evaluations, with MQM and BLEURT, respectively. BLEU is only here to have some points of comparison with the results presented in the PaLM paper. They comment that BLEU is misleading and would have changed their conclusions if they only based their evaluation on BLEU.
Interestingly, the authors didn’t set up any machine translation systems by themselves but chose instead translations submitted to WMT21 that are publicly available. This choice enables the reproducibility of their results.
They also evaluate Google Translate. Usually, I would argue that the evaluation of such a black box system can’t be credible since we don’t know whether it was trained on the evaluation data (i.e., plausible data leakage). The authors thought about this possible issue and confirmed that there isn’t any data leakage by directly consulting the Google Translate team. It may seem like an obvious step in an evaluation, but this is actually rarely confirmed by researchers who evaluate commercial systems.
I also note that they didn’t copy any number from previous work, i.e., all the scores were computed by the authors, in contrast to the evaluation reported in the PaLM paper, ensuring that all the scores are comparable.
This is one of the most scientifically credible evaluations I have seen in a machine translation research paper (believe me, I studied 900+ machine translation evaluations). To sum up, we have:
A manual evaluation with a state-of-the-art framework (MQM), and with detailed translation error counts
An automatic evaluation with a state-of-the-art metric (BLEURT)
A statistical significance testing with PERM-BOTH
The confirmation of the absence of data leakage
The availability of some of the evaluated translations for better reproducibility
The confirmation that the scores are all comparable, i.e., computed with the same metrics, tokenizations, etc.
The BLEU scoring with SacreBLEU, and the associated signature to ensure the reproducibility of the scores that enable comparisons in future work.
What Did They Conclude?
SOTA systems have a substantial advantage of between 1 and 3 BLEURT points over the best PaLM results, a gap that is reflected in their much lower MQM scores.
In other words, standard machine translation systems are significantly better than PaLM.
Even if we only look at the BLEU scores reported, the differences between PaLM and WMT21 systems seem outstanding.
This finding contradicts the evaluation performed in the PaLM paper (section 6.5) which found that PaLM outperforms previous best systems. The differences are that the evaluation in PaLM was only based on BLEU scores already computed for old machine translation systems and/or used uncomparable tokenizations…
Limits
The main limit of this work, and acknowledged by the authors, is that PaLM isn’t actually trained on independent sentences but on documents.
It is safe to assume that the gap in translation quality would be less dramatic between PaLM and standard machine translation systems if longer chunks of texts, to get more context, were translated by PaLM.
On the other hand, standard machine translation systems are trained on sentences considered independently.
Consequently, running and evaluating the systems at sentence-level biased the evaluation towards machine translation systems. Note: The original evaluation conducted in the PaLM paper was also conducted at sentence-level.
The evaluation also misses statistical significance testing for the results computed with automatic metrics. They appear significant in BLEU, but it is rather difficult to judge at a glance whether the differences in BLEURT are really significant. Note: I would say that they are significant, given the gaps observed between BLEU and MQM scores, but it should be confirmed.
To the best of my knowledge, the authors didn’t release the prompts and the translations generated by PaLM and used for the evaluation. I hope they will. It would allow the research community to study them and facilitate comparisons in future work using different metrics, similar to what Meta AI has done for No Language Left Behind.
This is especially needed since MQM evaluations are costly and difficult to reproduce. They also seem to have used a custom BLEURT model that is not (yet?) publicly available, preventing the reproduction of the BLEURT scores.
Conclusion
Standard machine translation systems remain better than large language models.
PaLM has been shown to be better at translation than other comparable models, such as FLAN and GPT-3. We can expect the conclusion drawn by Vilar et al. to be extendable to these other models.
Nonetheless, it is important to remember that machine translation systems and language models are not trained on the same data and have very different computational costs.
PaLM is a 540 billion parameter model but can translate without being directly trained on translations. On the other hand, machine translation systems have a much lower computational cost but do require a large amount of translations to be trained.