

Insights from the Falcons
Insights from the Falcons
How to pre-train large language models

The Falcon models are open large language models (LLMs) available in three sizes: 7B, 40B, and 180B parameters. They are performing among the best open LLMs on various tasks.
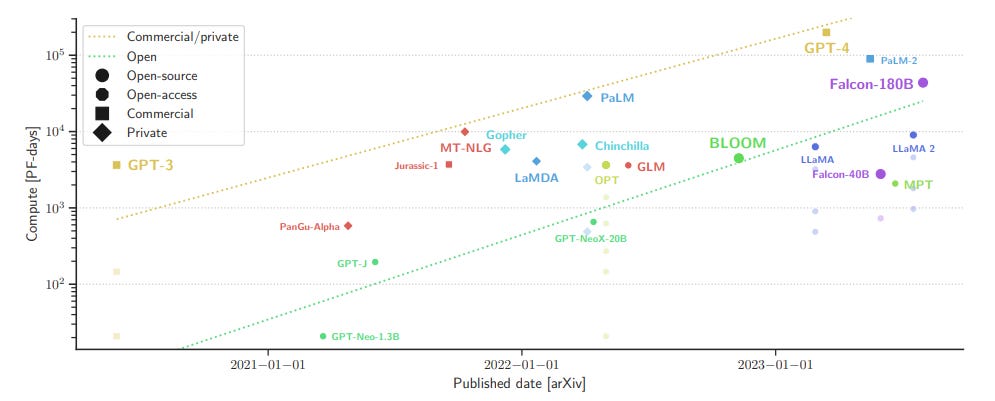
The lab behind them, the Technology Innovation Institute of Abu Dhabi, has already published an insightful paper detailing their process to build Falcon’s training data:
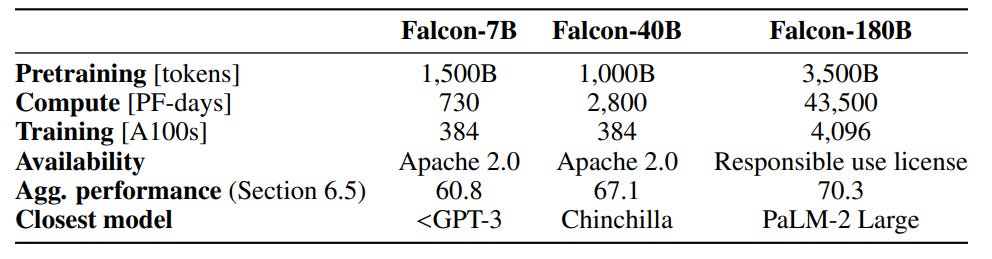
Then, three weeks ago, they finally published their long-awaited paper detailing their framework to select the training data, neural architecture, and hyperparameters for the Falcon models. Note: The Falcon’s model card shows “paper coming soon” since May 2023.
The Falcon Series of Open Language Models
It’s a particularly interesting “making of” the Falcon LLMs, but also a very long and verbose paper.
In this article, I review and summarize the paper. We will see what experiments the Falcon team did to decide and validate the training data, architecture, and training hyperparameters.
If you want to know how to use or fine-tune these models, have a look at these related articles:



Sourcing and Cleaning Training Data for Pre-training an English LLM
Building the dataset is the most critical step for training LLMs. Its construction mainly depends on what kind of tasks we want the models to achieve. We have several questions to answer, for instance:
Do we want the model to be multilingual or to focus on the English language?
Do we want the model to be good at coding?
Do we want the model to be multimodal?
etc.
The Falcon team created a dataset to train the model to be multilingual, including data in other European languages, and capable of coding.
But first, the model needs to be good for the English language. To achieve this, we need an extremely large quantity of English data.
Where can we find trillions of English tokens?
The Falcon team used Common Crawl which is also the source of many other datasets used to train LLMs. They have used a language identifier to get only English text and also filtered adult content.
They show that this first, almost raw, version of the dataset is not very good training data, as expected. However, applying filtering heuristics significantly improves the model. Finally, deduplicating the dataset further improves the results. Their final dataset, filtered and deduplicated, used to train the Falcon models is the RefinedWeb. They provide more details about it in this paper.
Compared to other datasets, such as C4 and The Pile, using RefinedWeb for training yields better LLMs.
They also observed that using heavily curated data for specific genres/domains, e.g., books, technical text, or conversations, doesn’t systematically improve the zero-shot performance of an LLM, i.e., on tasks for which the LLM is not specifically trained.
Coding and Multilinguality
To add multilingual and coding capabilities to the model, the training data must also contain code and text in other languages.
But does including other languages degrade the performance in English?
For instance, if we have 90% of the training data in English and 10% in other languages, how does the model perform compared to a model trained exclusively on 100% English data?
To answer this question, the Falcon team replaced 10% of the English data with data in German, Spanish, French, Italian, Dutch, Polish, Portuguese, Czech, Swedish, Romanian, Danish, Norwegian, Catalan, Slovene, and Bulgarian. They have found that it indeed decreases the performance in English but not significantly. For some evaluation benchmarks, there is no degradation.
They have similar observations for code. Having 5% of code in the training data does not impact the performance.
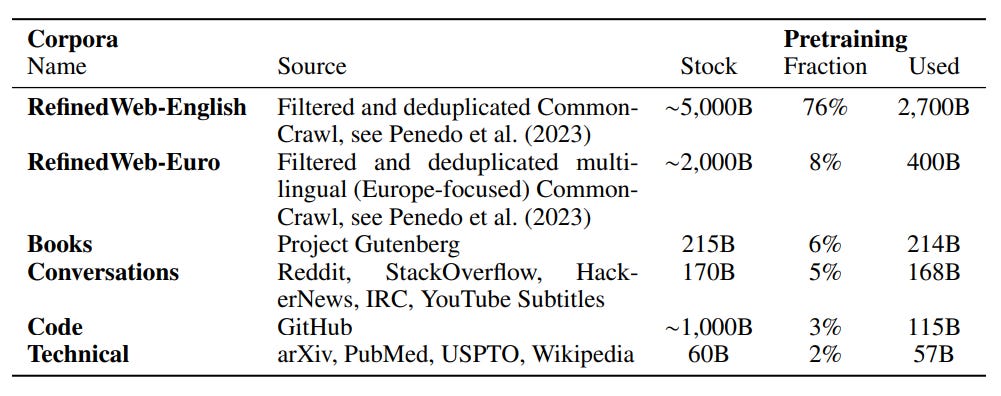
The final version of the dataset used to train the Falcon models includes 8% of multilingual data and 3% of code. These percentages are lower than the ones tested because they could not find enough data of high quality with their pipeline.
The complete data mixture used is as follows:
Neural Architecture
Grouped Query Attention
Initially, transformer models used the multi-head attention scheme, but Shazeer (2019) introduced multi-query attention, where the same keys and values are shared across attention heads, significantly reducing memory consumption during autoregressive generation. This modification, popularized by Google’s PaLM and Llama 2, improves the scalability of inference for large models by reducing memory usage (10-100x).
However, multi-query attention faces challenges in efficient parallelization, particularly with GPU-based tensor parallelism. To address this, the Falcon team proposed to separate key/value pairs for each tensor parallel rank, simplifying communication. The modification, also known as grouped query attention (GQA), reduces communication during training and inference. A similar approach was independently proposed by Ainslie et al., (2023).
GQA is now widely used by other LLMs, e.g., Mistral 7B and DeciLM 6B.
The Falcon team has validated that GQA only slightly degrades the performance of the model while significantly accelerating inference.
Rotary positional embeddings
Initially, the Transformer architecture used absolute sinusoidal embeddings to model token positions. However, relative embeddings have gained popularity over absolute ones in the community. Different models use various approaches for relative positional embeddings, such as ALiBi and Rotary Positional Embeddings (RoPE).
The Falcon team validated that RoPE outperforms ALiBi but for a higher computational cost. To mitigate this cost, they have implemented custom Triton kernels.
SwiGLU
For the activation functions, they tried SwiGLU but didn’t observe significant gains while it consumes much more memory. They didn’t use it.
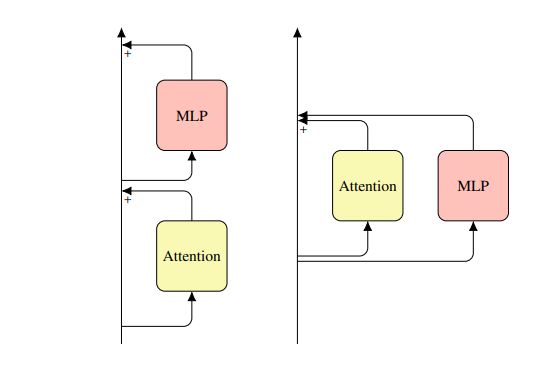
Parallel Attention and MLP Blocks
They validated that computing the attention and the MLP blocks in parallel doesn’t degrade the performance while it reduces the communication costs associated with tensor parallelism.
Biases Removal
Removing the biases in the linear layers and layer norms improves stability as found by the authors of PaLM.
They validated that removing the biases in the linear layer does not result in worse performance.
Training Hyperparameters
Z-loss
The z-loss increases the stability of training, by encouraging the logits to stay close to zero.
They validated that it did not impact the zero-shot performance of the models and implemented it for improved stability.
Weight Decay
The purpose of weight decay is to prevent overfitting by penalizing overly complex models. When training a transformer, the model is optimized to minimize a loss function that measures the difference between the predicted output and the actual target. The weight decay term is then added to this loss, proportional to the square of the magnitude of the model's weights.
A higher weight decay discourages strong updates of the model weights.
They simply fixed it to 0.1 with AdamW.
Learning Rate
This is one of the most important hyperparameters for training.
A high learning rate poses a risk of divergence and training instabilities, while a low learning rate sacrifices performance, resulting in inefficient training. The goal is to balance these extremes for optimal training outcomes.
The authors used a simple grid-search approach to find a good learning rate (they tried more principled approaches but failed to obtain good results).
They chose several learning rates to try and picked the one that yielded the best results after a training warmup performed with 500 million tokens. They found this strategy to yield consistent results with the results obtained after a complete training, as shown in the following table, for a 1B parameter model:
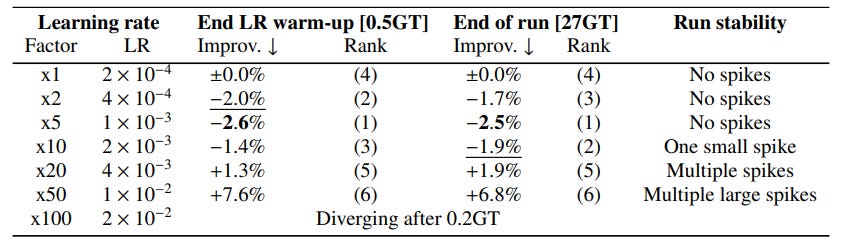
Summary and Conclusion
This table summarizes the main choices made to create the Falcon models:
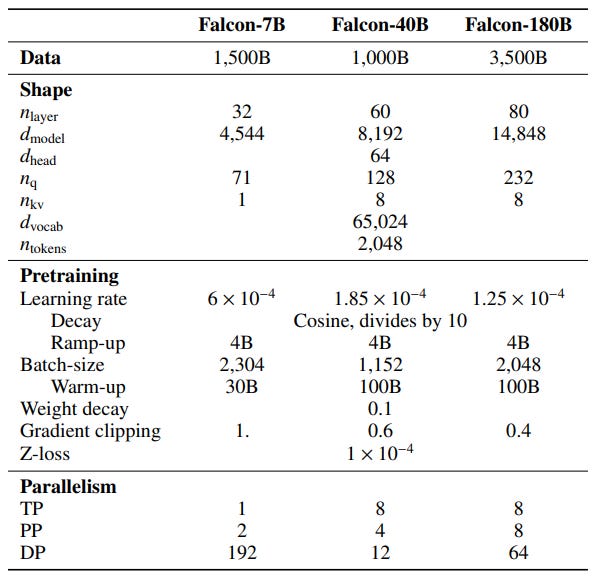
We can’t apply the exact same hyperparameters to other LLMs but the methodology used to find them can be reused. It also gives a good idea of what architectures and hyperparameters might work well for these sizes of models and datasets.
The remainder of the paper is mainly dedicated to other choices related to their multi-GPU setting. I won’t comment on it to keep this article short but I recommend reading Section 5.3 if you are interested in optimizing the training of LLMs using multiple GPUs.
There is also a large part of the paper dedicated to the evaluation of the Falcon models. I did not find this part very insightful. It only shows that the Falcon models are better than some other LLMs on some public benchmarks without much analysis.
Note: The Falcon team presents the Falcon models as “open-source”. While I agree that they are among the most “open” LLMs, they are still far from being “open-source”. Even with all the details in the paper, this is impossible to reproduce by ourselves the Falcon training. We miss, at least, the complete exact training data (“RefinedWeb” is only a part of it) and the training source code.
I think the issue with multi-query is more about quality than parallelization, because you’re basically using the same K & V values for everything. With grouped query attention, you take an approach that is between multi query and multi head.