

LoftQ: Better Initialization for a Quantization-Aware LoRA
LoftQ: Better Initialization for a Quantization-Aware LoRA
Experiments with Mistral 7B


QLoRA is now prevalent for fine-tuning large language models (LLMs) on consumer hardware. This method first quantizes the LLM to 4-bit (or lower precision), freezes its parameters, and then fine-tunes a LoRA adapter on top of it.

The main weakness of QLoRA is that it is quantization-unaware. The model is quantized and then the adapter is initialized, separately. Ideally, we would like the quantization and initialization to be performed jointly.
Several methods have been proposed to make QLoRA quantization-aware. I’ve already covered in the Kaitchup two interesting works addressing this issue: QA-LoRA and LQ-LoRA. Unfortunately, none of these methods became widely adopted. Their official implementation is not maintained and they can only be applied to a handful of LLMs.


In this article, I present LoftQ, yet another method to fine-tune quantization-aware adapters. This method has a lot of similarities with LQ-LoRA but LoftQ is supported by Hugging Face’s PEFT and regularly updated. LoftQ is getting easier to use and can be applied to most LLMs supporting QLoRA’s NF4 quantization. We will see how to apply it to Mistral 7B and check its performance against standard QLoRA. A 12 GB GPU is enough to run LoftQ for a 7B model.
The notebook demonstrating LoftQ fine-tuning with Mistral 7B is here:
LoftQ: Reducing the Discrepancies Between the Quantized LLM and LoRA
LofQ stands for LoRA-Fine-Tuning-aware Quantization. It is described by Microsoft in this arXiv paper:
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
It has many similarities with LQ-LoRA. The main one is that it decomposes the LLM weights into a quantized matrix and a set of matrices A and B that are components of LoRA.
The main difference is in how a good decomposition is obtained. LoftQ first quantizes the LLM, W into W’, and then it searches for A and B so that W’+B+A is as close as possible to W. Several iterations are performed. Note: I spared you the maths here. A Frobenius norm is involved and singular value decomposition (SVD) is performed. If you want to know more, Section 3 of the paper explains the method very well I think, if you are familiar with matrices.
The method itself doesn’t find the optimal decomposition but a good approximation. It makes it much less costly to run than LQ-LoRA. Moreover, the authors found that even if we just quantize W into W’ as QLoRA would do, so without searching for better quantization, we can still find reasonably good A and B with LoftQ.
According to experiments run by the authors, LoftQ performs better than QLoRA and further closes the gap with full fine-tuning, especially when a low-precision quantization is performed. Here are some results for different quantization precisions using Llama 2 7B and 13B.
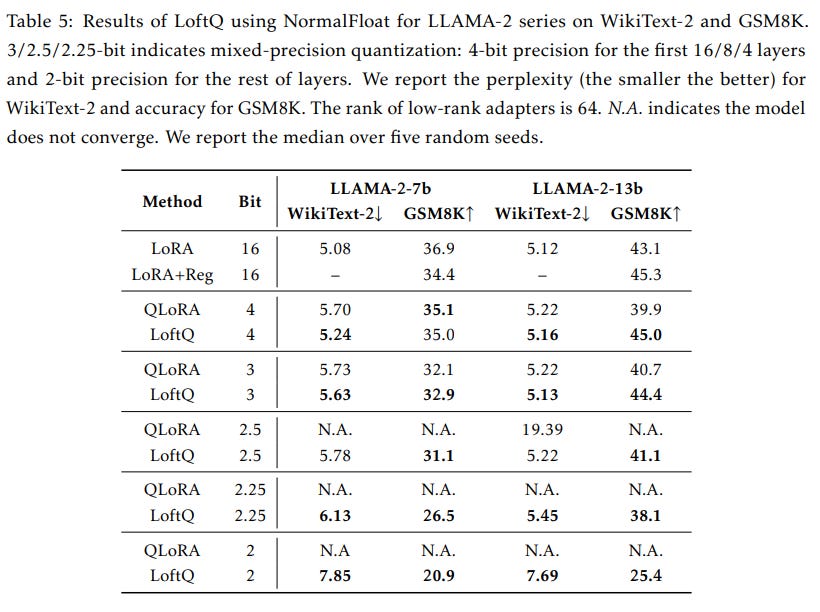
LoftQ in Practice with PEFT
LofTQ is supported by Hugging Face PEFT. Using PEFT, fine-tuning an adapter with LofQ is very similar to fine-tuning with QLoRA.
I applied LoftQ to Mistral 7B. My code is based on the same code I used to fine-tune Mistral 7B with QLoRA. As you will see, there is not much to modify.

We will see two different methods to apply LoftQ:
A simple method replacing on-the-fly QLoRA’s weights with LoftQ’s weights: This method has the advantage that it doesn’t consume more memory since we only load the model once. However, it doesn’t search for a better quantization but directly replaces the weights with weights that yield a better initialization of LoftQ, without iterating.
The full LoftQ with iterations searching for the best quantization and initialization of the adapter: This is more complex and consumes a lot of CPU memory since we need to fully load the model without quantizing it. For a 7B model, you will need between 30 GB and 38 GB of CPU RAM.
For the simple method, we just have to load the model as we would normally do with QLoRA.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name, quantization_config=bnb_config, device_map={"": 0}, attn_implementation=attn_implementation
)
model = prepare_model_for_kbit_training(model)
#Configure the pad token in the model
model.config.pad_token_id = tokenizer.pad_token_idThen, define your LoRA configuration:
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate_proj", "down_proj", "up_proj"]
)Now, using this LoraConfig, we can create a peft model, i.e., a model with an adapter loaded on top of it.
peft_model = get_peft_model(model, peft_config)At this point, the model is quantized with the standard QLoRA method and the adapter is initialized with standard LoRA.
Next, we apply one iteration of LoftQ searching for a better initialization of LoRA’s parameters so that the sum of the model’s quantized weights and LoRA’s weights is closer to the original non-quantized weights of the model.
This is simply done with this method:
replace_lora_weights_loftq(peft_model)It modifies the model in place. It takes only a few minutes.
After that, the model is ready for training:
training_arguments = TrainingArguments(
output_dir="./results/",
evaluation_strategy="steps",
do_eval=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=12,
gradient_accumulation_steps=2,
per_device_eval_batch_size=12,
log_level="debug",
logging_steps=50,
learning_rate=1e-4,
eval_steps=50,
num_train_epochs=1,
save_strategy='epoch',
warmup_ratio=0.1,
lr_scheduler_type="linear",
)
trainer = SFTTrainer(
model=peft_model,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
dataset_text_field="text",
max_seq_length=512,
tokenizer=tokenizer,
args=training_arguments,
)
trainer.train()It yields the following logs:

Let’s compare them to the logs obtained with the standard QLoRA fine-tuning:
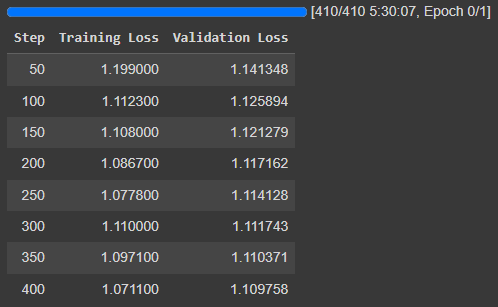
It’s not significantly different. We could say that QLoRA in the end yields a slightly lower loss. One iteration of LoftQ might not be enough to get better results than standard QLoRA.
Let’s see what happens when applying several iterations, i.e., the full LoftQ.
Hugging Face prepared a script for this. To get it we need to clone the PEFT repository first:
git clone https://github.com/huggingface/peft.gitThe following script will search for a better initialization of LoftQ:
python peft/examples/loftq_finetuning/quantize_save_load.py \
--model_name_or_path mistralai/Mistral-7B-v0.1 \
--bits 4 \
--iter 5 \
--rank 16 \
--save_dir "./loftq_iters/"It applies 5 iterations. This is enough according to the paper describing LoftQ. The resulting model and LoRA adapter are saved in the “./loftq_iters/”.
The model is not serialized in 4-bit by the script but with fp16 parameters. I assume that when they developed this script, 4-bit serialization was not yet supported by bitsandbytes.
Running this script will consume around 36 GB of CPU RAM and take around 30 minutes to complete on Google Colab. It can be much faster if you use a recent CPU.
Here is the full code to fine-tune this new model with a better initialized LoRA:
import torch
from datasets import load_dataset
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from trl import SFTTrainer
MODEL_DIR = "./loftq_iters/Mistral-7B-v0.1-4bit-16rank"
#Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, add_eos_token=True, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'left' #Necessary for FlashAttention compatibility
#Better to use bf16 if supported (Ampere GPUs or more recent)
#If bf16 is supported, the GPU is also recent enough to support FlashAttention
if torch.cuda.is_bf16_supported():
compute_dtype = torch.bfloat16
attn_implementation = 'flash_attention_2'
else:
compute_dtype = torch.float16
attn_implementation = 'sdpa'
dataset = load_dataset("timdettmers/openassistant-guanaco")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_DIR, quantization_config=bnb_config, device_map={"": 0}, torch_dtype=compute_dtype, attn_implementation=attn_implementation
)
model = prepare_model_for_kbit_training(model)
#Configure the pad token in the model
model.config.pad_token_id = tokenizer.pad_token_id
peft_model = PeftModel.from_pretrained(
model,
MODEL_DIR,
subfolder="loft_init",
is_trainable=True,
)
training_arguments = TrainingArguments(
output_dir="./results_loftq/",
evaluation_strategy="steps",
do_eval=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=12,
gradient_accumulation_steps=2,
per_device_eval_batch_size=12,
log_level="debug",
logging_steps=50,
learning_rate=1e-4,
eval_steps=50,
num_train_epochs=1,
save_strategy='epoch',
warmup_ratio=0.1,
lr_scheduler_type="linear",
)
trainer = SFTTrainer(
model=peft_model,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
dataset_text_field="text",
max_seq_length=512,
tokenizer=tokenizer,
args=training_arguments,
)
trainer.train()It yields the following logs:
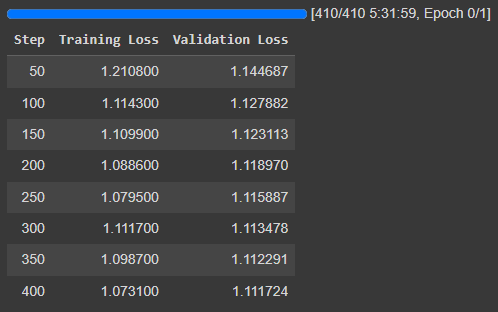
Again, it doesn’t yield a lower loss than the standard LoRA.
Is LoftQ really working?
I assume that the QLoRA’s quantization error for Mistral 7B is simply too low for LoftQ to have a significant impact here. QLoRA 4-bit is probably already good enough. In other words, initializing LoRA’s parameters at 0 yields a combination (LLM’s quantized weights + LoRA’s weights) that is already very close to the original non-quantized weights of the models. We could express it as follows:
QLoRA = Mistral 7B’s quantized weights + LoRA’s initial weights
= Mistral 7B’s quantized weights + 0
= Mistral 7B’s quantized weights
≈ Mistral 7B
In the paper, the results with 3-bit and 2-bit quantization are much more impressive than with 4-bit quantization. This is because the quantization error is much higher with lower precision. A better initialization of LoRA with LoftQ significantly helps in this scenario.
Unfortunately, at the moment, bitsandbytes and PEFT only support 4-bit quantization. We can’t experiment with 2-bit and 3-bit quantization.
Conclusion
In theory, LoftQ is better than the standard LoRA. However, with 4-bit quantization and 7B LLM, or larger, the benefits from LoftQ might not be significant enough to be noticeable.
For smaller LLMs, LoftQ might yield better results since smaller models are more difficult to quantize. Nonetheless, since LoftQ minimizes the quantization errors, in theory, I would recommend always using it.
Next week, I’ll publish a follow-up article comparing more extensively LoftQ with QDoRA and QLoRA and showing how to properly merge the adapters fine-tuned with these methods.

I am looking to run a fine-tuned small language model on an edge device. The edge device is limited, so I am obviously looking to quantize.
To be efficient, I prefer to keep the quantized base model on the hardware and if I need to push updates or adjust the finetune, solely push LoRA Adapters and allow the ‘merge’ or ‘apply’ process take place on the edge.
This eliminates me having to push an entire base model + LoRA Adapter and simplifies the send to only the LoRA Adapter.
I know this is possible, but I want to limit the degradation of performance since applying a naïve adapter to a quantized model has repercussions as you’ve noted.
Could you expand on this comment: "Note: If you plan to release your model fine-tuned with LoftQ, you will need to release the model along with your adapter. The model itself is also modified."
In what way is the base model changed? Could you link to the source for this?