

Run Llama 2 Chat Models on Your Computer
Run Llama 2 Chat Models on Your Computer
State-of-the-art AI on a budget

LLaMa 2 is out and it outperforms the previous version.
It also outperforms the Falcon models that were considered the best for many natural language generation tasks.
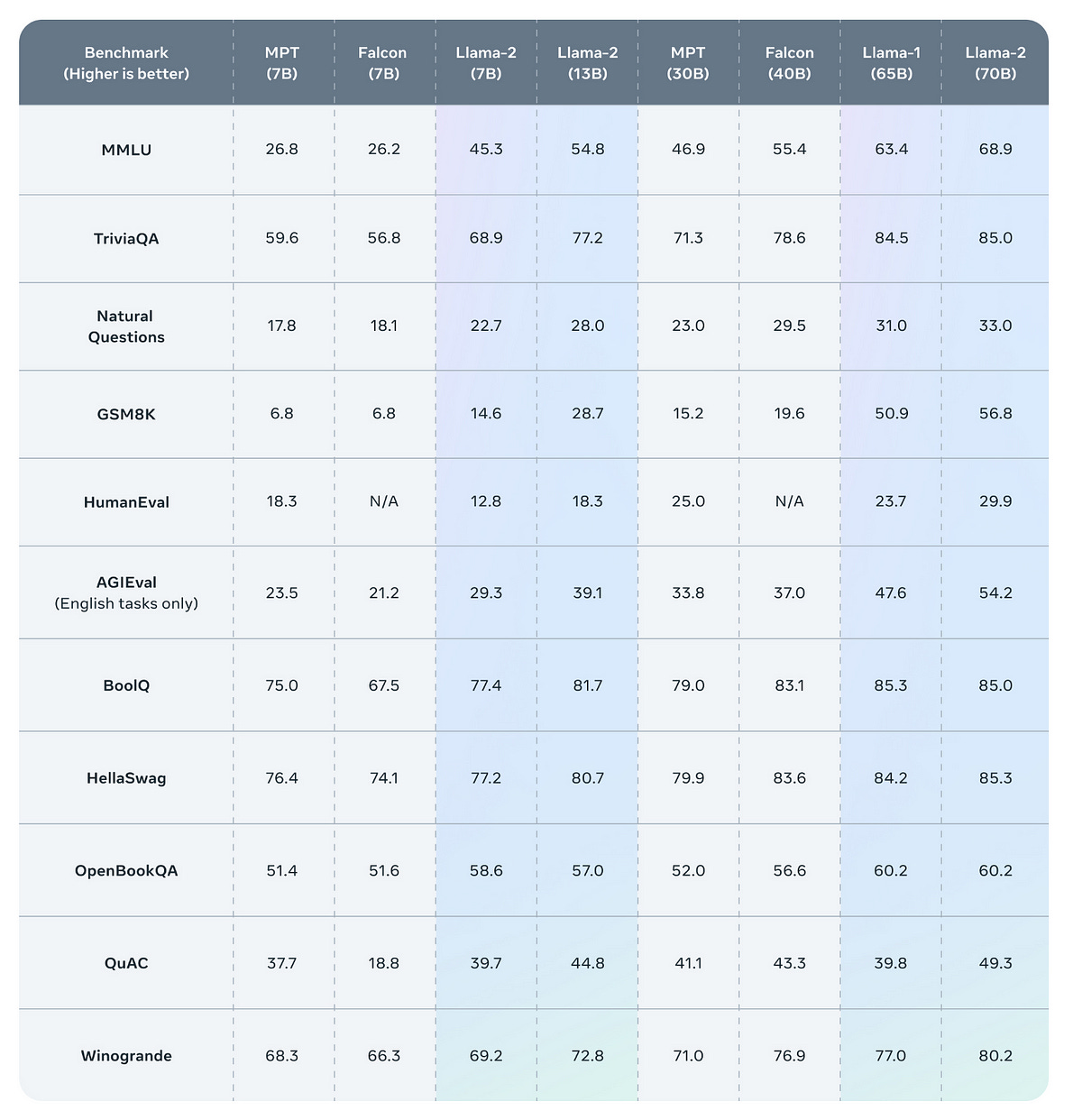
It is especially interesting to compare models of the same sizes. If we look precisely at Falcon-7B against Llama-2–7B, Llama 2 is the clear winner on all tasks.
Also, while Llama 1 was available only as a very large language model (LLM) with 65B parameters, Llama 2 has been released by Meta in 3 different versions: 7B, 13B, and 70B. They have also released the instruct versions of these models that Meta calls Llama Chat.
The 70B version would run only on costly hardware, even after quantization at a low precision the model remains very big.
However, the 7B and 13B versions leave the possibility to run Llama 2 on consumer hardware.
In this short blog post, I show how you can run Llama 2 on your GPU.
Note: Llama 2 is not fully open. You must register yourself to get it. If you work for an extremely large online company, Meta may reject your application (see the last section of this article).
Run Llama 2 with 4-bit quantization on your GPU
Note: The corresponding notebook is available here. (Notebook #4)
The following code uses only 10 GB of GPU VRAM. It can run on a free instance of Google Colab or on a local GPU (e.g., RTX 4060 16GB (affiliate link), the RTX with the highest VRAM below $500).
We only need the following libraries:
transformers
accelerate (for device_map)
bitsandbytes (for 4-bit quantization)
pip install transformers accelerate bitsandbytesWe will run the 7B version of Llama 2 Chat. Since the model is not fully open, you need to register on Meta’s website and then validate your registration on hugging face to get the model from the hub.
You can find more information about this procedure at the top of this model card: https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Llama-2-7b-chat-hf"
prompt = "Tell me about gravity"
#Replace by your Hugging Face access token (this is mine, revocated of course)
access_token = "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" Then, we load the model from the hub:
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True, use_auth_token=access_token)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True, use_auth_token=access_token)
model_inputs = tokenizer(prompt, return_tensors="pt").to("cuda:0")We can generate the output as follows:
output = model.generate(**model_inputs)
print(tokenizer.decode(output[0], skip_special_tokens=True))It should be very fast.
What about the license?
One of the main criticisms against the first version of Llama is that it is distributed under a license that doesn’t allow commercial use.
Meta understood that in order to be truly open, an LLM should be distributed under a more permissive license.
Meta did not choose an existing license but created one specifically for Llama 2. You can find it here. TL;DR You can use it for commercial purposes without restrictions.
One quirk of the license is that if your company’s services have more than 700 million monthly active users, Meta may not grant you the right to use Llama 2. With this move, Meta clearly aims at preventing their competitors (Google, Twitter, Amazon, Telegram, TikTok, …) from exploiting Llama 2 to improve their products.