

SqueezeLLM: Better 3-bit and 4-bit Quantization for Large Language Models
SqueezeLLM: Better 3-bit and 4-bit Quantization for Large Language Models
As fast as AWQ, but more accurate


Large language model (LLM) quantization is a necessary step to run a very large language model on consumer hardware. It was a very active research area in 2023 with several new algorithms to make 4-bit models more accurate, faster, and trainable.
In previous articles, I especially worked with BnB’s NF4, GPTQ, and AWQ for 4-bit quantization.


In particular, AWQ is a quantization method that yields fast and accurate 4-bit models. It is well-supported by many deep learning libraries such as vLLM and Transformers.
However, AWQ is not the most accurate method. Regular progress is made in making quantization more accurate and I expect 2024 to be even more fruitful for 3-bit and 4-bit quantization.
In this article, I present SqueezeLLM. It is one of the most recent quantization methods yielding quantized LLMs even more accurate than AWQ. I first explain how SqueezeLLM works and then discuss its results compared with previous quantization methods. We will also see how to quantize Llama 2 with this method.
The following notebook runs the 3-bit and 4-bit quantization for Llama 2 using SqueezeLLM:
Dense and Sparse Quantization
SqueezeLLM is presented in this paper:
SqueezeLLM: Dense-and-Sparse Quantization
It’s the combination of two techniques.
SqueezeLLM quantization is non-uniform. To be more sensitive to the importance of the weights, it first clusters the weights with a weighted k-means where the centroids of the cluster are close to the sensitive weights. This clustering itself already achieves a much more accurate quantization than naive uniform quantization. Note: This clustering sounds simple but it’s not. The method employs a Taylor expansion with gradient approximation and an approximation to the Hessian based on the Fisher information. See the paper for the equations.
The core approach of SqueezeLLM relies on a second technique decomposing the weight matrix of the model into dense and sparse matrices. The sparse matrix is tiny as it only contains the weight outliers while the dense matrix contains all the remaining weights. The dense matrix can be quantized very efficiently while the sparse matrix is not quantized.
This decomposition only adds little overhead to the quantization process since the outliers are few. Even with aggressive quantization, rarely more than 0.5% of the weights will be considered sparse. This sparse component can be efficiently stored using techniques like the compressed sparse row (CSR) format. For inference, the decomposition allows for the simultaneous processing of dense and sparse matrix multiplications, improving efficiency, especially since the sparse part can utilize specialized sparse computing methods.
Furthermore, this method separately handles a small fraction (e.g., 0.05%) of highly sensitive weights, ensuring they are precisely represented to avoid errors. This approach serves a dual purpose: it minimizes the impact of these sensitive values on the model's output and prevents them from distorting the quantization process for the remaining weights. These highly sensitive weights are not quantized.
The following table by the authors shows how well SqueezeLLM performs compared to previous work on quantization:
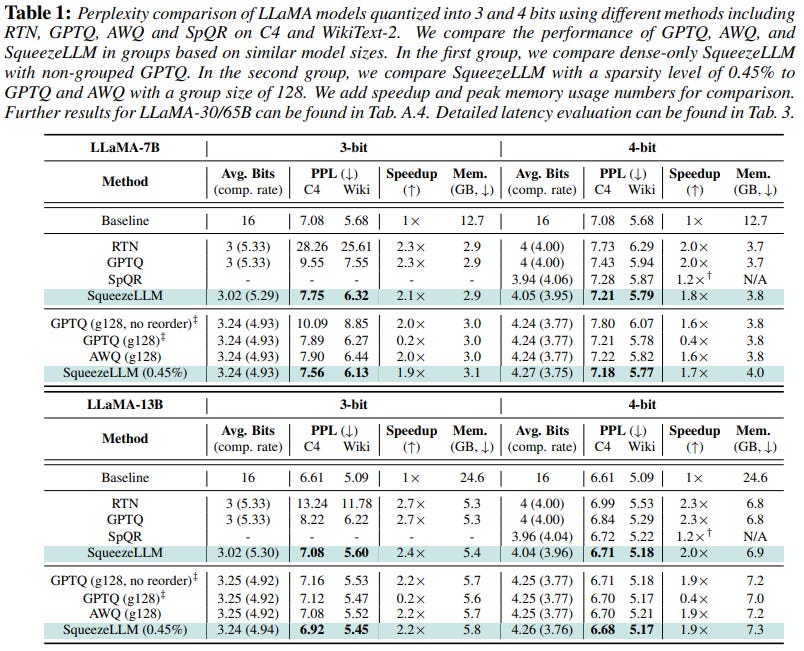
Note: “PPL” is the perplexity achieved by the model on the C4 and Wiki datasets. Lower PPL is better.
Thanks to the implementation of CUDA kernels to speed up inference, SqueezeLLM is as fast as AWQ which also relies on custom CUDA kernels. Models quantized with SqueezeLLM consume slightly more memory than with AWQ (+200 MB at most) since a larger number of weights are not quantized.
SqueezeLLM appears as memory-efficient and fast as AWQ. However, it seems significantly more accurate. The perplexity achieved by SqueezeLLM models is lower than with AWQ on C4 and Wiki, for Llama 2 7B and 13B, and for both 3-bit and 4-bit quantization.
The perplexity achieved by the 3-bit models is particularly impressive. The perplexity of SqueezeLLM at this precision is much closer to the baseline than AWQ.
Quantize with SqueezeLLM
The authors released their code for quantization here:
GitHub: SqueezeAILab/SqueezeLLM (MIT license)
I tried it and confirmed that it works. Let’s see how to quantize Llama 2 7B to 3-bit and 4-bit with SqueezeLLM. Note: The implementation only supports Llama 2, OPT, and Mistral 7B for now.
First, we must calculate the Fisher sensitivity scores (gradient square) of the Llama 2 7B. This is done with SqueezeLLM-gradients that we have to install as follows:
git clone https://github.com/kssteven418/SqueezeLLM-gradients.git
cd SqueezeLLM-gradients && pip install -e . && pip install -r requirements.txt
pip install accelerateThen, run:
CUDA_VISIBLE_DEVICES=0 python SqueezeLLM-gradients/run.py --output_dir llama-gradients --model_name meta-llama/Llama-2-7b-hf # single GPUThis will save the results in a folder named llama-gradients. This step requires a GPU with at least 24 GB of VRAM. It can take several hours to complete with a very slow CPU.
Once it’s done, install SqueezeLLM:
git clone https://github.com/SqueezeAILab/SqueezeLLM.git
cd SqueezeLLM && pip install -e .
cd SqueezeLLM/squeezellm && python setup_cuda.py installTo lower the memory usage, the framework splits the model at the layer level. We must do this chunking for the original model and the model’s gradients computed earlier:
python SqueezeLLM/quantization/chunk_models.py --model meta-llama/Llama-2-7b-hf --output llama-chunks --model_type llama
python SqueezeLLM/quantization/chunk_models.py --model llama-gradients --output llama-gradients-chunks --model_type llamaThis should only take a few minutes. The layers are saved in two new folders: llama-chunks and llama-gradients-chunks.
The next step finds the outlier parameters in the model. We have to run this script:
python SqueezeLLM/quantization/generate_outlier_config.py --model llama-chunks --range 1.8 --output llama-chunks-outlierconfig/Note that the framework has a strange way of finding the outliers for each layer. “range” is not a range. Rather than setting a given percentage of outliers, we must choose this threshold value (“range”) that is recommended to be between 1.5 and 2 (as defined in Section 4.2 of the paper presenting SqueezeLLM). Then, it will save a JSON file to store the outlier data identified in the model. Depending on the value, you may get a lot of outliers, which will increase the model size. For Llama 2, I set this value to 1.8 and got 0.53% of outliers.
Decrease this value if you have more memory and want a more accurate model.
“generate_outlier_config.py” will save a JSON file in llama-chunks-outlierconfig containing the information needed for the dense-and-sparse quantization.
We also need to cluster the parameters with k-means as described in the previous section for a non-uniform quantization (nuq):
python SqueezeLLM/quantization/nuq.py --bit 4 --model_type llama --model llama-chunks --gradient llama-gradients-chunks --output llama-LUT-4bit/ --outlier_config llama-chunks-outlierconfig/outlier_config_o0.53.json --sensitivity 0.05Change “bit” to 3 if you want to quantize to 3-bit.
“sensitivity” is the fraction of important parameters that we want to spare from quantization in the dense matrix. A higher value will create a more accurate but bigger model.
This step takes several hours if you use an old CPU like the one of Google Colab. You don’t need a GPU for this step.
Then, the last step consists of rebuilding the model with quantized layers:
python SqueezeLLM/quantization/pack.py --model meta-llama/Llama-2-7b-hf --wbits 4 --folder llama-LUT-4bit/ --save llama-squeezed --include_sparse --balanceChange “wbits” to 3 for a 3-bit quantization. It will save the quantized model to a new file “llama-squeezed”.
Running a Model Quantize with SqueezeLLM
Nothing clearly indicates in the documentation of SqueezeLLM how to run the quantized models. I tried Hugging Face Transformers with some of the models released by the SqueezeLLM team such as squeeze-ai-lab/sq-llama-2-7b-w4-s0. As expected,d it doesn’t work. It tries the cast the model’s weights to another datatype which causes out-of-memory errors.
So, how can we run SqueezeLLM models?
A solution would be to adapt the code from the llama.py file that they used for benchmarking.
A simpler solution would be to use vLLM, a very fast framework for serving LLMs. SqueezeLLM is supposed to be supported but I didn’t try it yet. We will see how it works in the next article.
Conclusion
We saw how SqueezeLLM works. Preserving the weight outliers in a sparse matrix is very intuitive. To the best of my knowledge, the performance of this method for 4-bit and 3-bit quantization is still unmatched today. It yields models as fast as AWQ while being more accurate.
Nice piece, as usual!
Am I reading the results correctly? I see that AWQ is only a little bit higher in terms of perplexity.
vLLM recently optimized its use of AWQ. I wonder if/when they'll do the same for SqueezeLLM. https://github.com/vllm-project/vllm/pull/2566