

The Weekly Kaitchup #10
The Weekly Kaitchup #10
Zephyr 7B - LongLLMLingua - gte-tiny - Mistral 7B paper - OpenWebMath


Hi Everyone,
In this edition of The Weekly Kaitchup:
Zephyr 7B: first 7B LLM to outperform Llama 2 70B
Small and accurate embeddings with gte-tiny
LongLLMLingua: prompt compression for longer contexts
The publication of the paper describing Mistral 7B
A new dataset containing all the math documents from Common Crawl
The Kaitchup has now 754 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
If you are a monthly paid subscriber, switch to a yearly subscription to get a 17% discount (2 months free)!
Zephyr 7B: First 7B LLM to Outperform Llama 2 70B
Hugging Face also makes LLMs. Their new model, Zephyr 7B, has only 7 billion parameters but outperforms Llama 2 70B, a 70 billion parameter model, in writing, STEM, extraction, coding, and roleplay. It seems a bit behind for reasoning and math but, given that it’s a model 10 times smaller, that’s still quite impressive.

The base model is Mistral 7B. Hugging Face has fine-tuned it with supervised fine-tuning (SFT) on the UltraChat dataset. Then, to align the model with RLHF, they didn’t use the standard PPO but Direct Preference Optimization (DPO) instead. DPO is much simpler than PPO. For DPO, they used the dataset UltraFeedBack.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al., 2023)
Hugging Face has released Zephyr 7B with a license cc-by-nc 4.0 (we can’t use it for commercial purposes).
If you are interested in training your own RLHF model, have a look at my previous article using DeepSpeed Chat with PPO:

gte-tiny Embeddings
If you are interested in small and accurate embeddings, have a look at gte-tiny. They are available on the Hugging Face Hub:
This is a sentence-transformer model that performs as well as OpenAI embeddings.

You can use this model to map sentences, paragraphs, and documents, to a 384-dimension space.
LongLLMLingua: Prompt Compression for Longer Contexts
I hope someone has already started to write a survey on techniques extending LLMs’ context. There are so many that it’s challenging to keep track of all the advances. Many research papers share similar ideas but we lack clear comparisons of all techniques to understand which one is the best for a given scenario.
This work by Microsoft doesn’t explicitly increase the context length but compresses it by dividing by 4 (on average) its number of tokens.
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression (Jiang et al., 2023)
Since the prompts are compressed, we can feed longer prompts to LLMs. A side effect is that the latency of the LLM, i.e., the time we have to wait before it generates the first token, is also reduced since the context is smaller and thus faster to process.
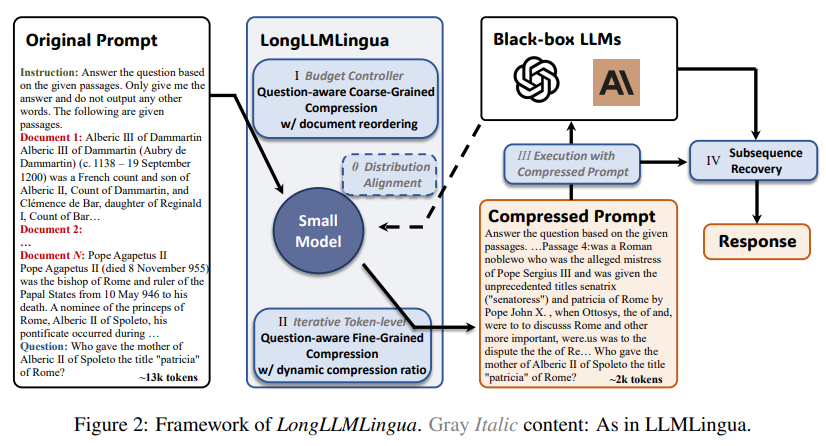
Microsoft released an implementation of LongLLMLingua on GitHub (MIT license).
Mistral 7B Paper
Mistral AI published the paper describing their Mistral 7B. You can find it on arXiv:
Mistral 7B (Jiang et al., 2023)
Mistral 7B is a very good (and fast) LLM outperforming larger ones. However, you won’t find why in this paper... They didn’t disclose anything new from what they have already published in their blog post or the Mistral 7B model card.
I assume that Mistral 7B performs very well thanks to very good training data, probably generated by larger models, similar to what Microsoft did to train phi-1.5. But this is really just an assumption since the paper doesn’t mention anything about the training data.

OpenWebMath: 14.7 tokens of math
“All the Math of Common Crawl” is in OpenWebMath. It’s the largest corpus of math documents. The dataset is described in this paper:
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text (Paster et al., 2023)
It contains 14.7B tokens crawled from Wikipedia, nLab, MathHelpForum, MathOverflow, blogs (WordPress, Blogspot), and more.
The equations in the dataset are formatted with LaTeX.
It is available on the Hugging Face Hub:
For instance, it can be used to better pre-trained/fine-tune models for mathematical reasoning.
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!
Is there a GitHub repo for doing DPO?