

The Weekly Kaitchup #15
The Weekly Kaitchup #15
Intel NeuralChat 7B - Tiny Random LLMs - Simpler Transformer


Hi Everyone,
In this edition of The Weekly Kaitchup:
NeuralChat 7B: Distilled DPO by Intel
Tiny Random LLMs for Debugging
Simpler Transformer Blocks
The Kaitchup has now 1,064 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
If you are a monthly paid subscriber, switch to a yearly subscription to get a 17% discount (2 months free)!
Intel NeuralChat 7B: Intel’s Chat Model Trained with DPO
The new chat model released by Intel is now at the top of the OpenLLM leaderboard (among the 7B models).
To achieve this performance, Intel used a strategy similar to what Hugging Face did to train Zephyr 7B:
Supervised fine-tuning (SFT) of Mistral 7B on a dataset generated by other LLMs
DPO training, using the model trained with SFT as a reference model, on a dataset also generated by other LLMs
The main differences with Zephyr 7B are in the hyperparameters and the datasets. For steps 1 and 2, Intel used the following datasets:
Intel/orca_dpo_pairs: In this dataset, Intel systematically chose the output of ChatGPT for the “chosen” output and the output of Llama 2 13b for the “rejected” output. In other words, they assumed that ChatGPT is always better than Llama 2 13b, which of course might not always be the case. While I expect this strategy to introduce some noise in the DPO training data (with some Llama 2 13b’s outputs better than ChatGPT’s outputs), it seems to have worked very well given the performance of NeuralChat.
If you want to train a similar model using these datasets, have a look at my tutorial and recipe for (distilled) DPO training:


Intel’s NeuralChat is available on the Hugging Face hub:
Intel/neural-chat-7b-v3 (Apache 2.0 license)
You can find more details about the model in this blog post:
Supervised Fine-Tuning and Direct Preference Optimization on Intel Gaudi2
Fast Debugging with a Tiny Random LLM
If you only need to test whether your code works for a particular model architecture, you may not need to use a real model for testing.
Imagine that you want to test whether your code runs with Llama 2 model’s architecture. In that case, you can start your testing with a placeholder LLM that looks like Llama 2. It can be an LLM with a tiny amount of parameters that are much easier and faster to handle but with the same architecture as Llama 2.
You can find such placeholder LLMs on the Hugging Face hub thanks to Stas Bekman. For instance, you can find a tiny random Llama 2 with only 100k parameters (less than 1 MB on the hard drive):
You can even make a random model by yourself using this script:
https://github.com/stas00/ml-engineering/blob/master/transformers/make-tiny-models.md
Simpler Transformer: 15% Faster and 15% Smaller
A Transformer has numerous modules and connections. We can illustrate it as follows:
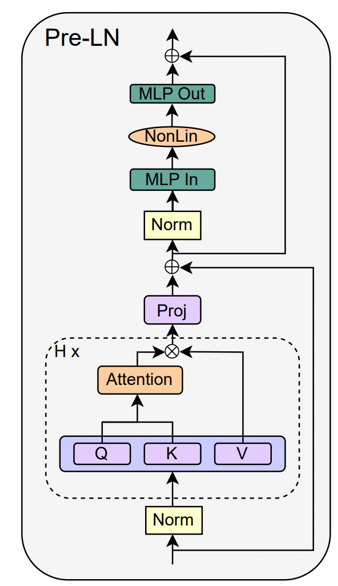
A recent work by He and Hoffmann (ETH Zurich) simplifies it by removing all the skip connections and normalization layers. They also rearrange the architecture so that the MLP and attention modules are used in parallel.
The authors illustrate it as follows:
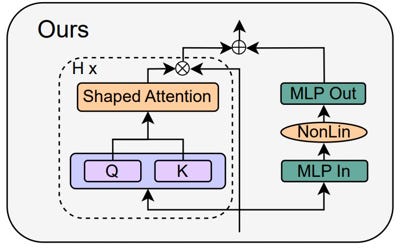
According to the authors, it makes the Transformer 15% faster for inference with 15% fewer parameters while preserving the same performance. The training speed remains the same, i.e., the modifications don’t make it slower to converge.
The paper is also very interesting to read, especially if you are curious about the small details that make the Transformer model:
Simplifying Transformer Blocks
What To Read On Substack


That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!