

The Weekly Kaitchup #2
The Weekly Kaitchup #2
Prompts of unlimited length for Llama 2 - Synthetic instruction dataset - Open multilingual QA dataset

In The Weekly Kaitchup, I briefly comment on recent scientific papers, new frameworks, tips, open models/datasets, etc. for affordable and computationally efficient AI.
In this edition, I present:
Unlimiformer: Encode prompts of any length
A “new” method to generate synthetic instruction dataset
A new multilingual QA dataset (a synthetic one)
A brief explanation of why using the CPU for inference is not as slow as you may think
A tip to avoid overflow issues with SFTTtrainer
If you like reading The Kaitchup and find it useful, share it with your coworkers and friends, or on your favorite social network, by clicking this button:
Thank you for your support!
Unlimiformer for LLama-2: Encode Extremely Long Input
Large language models have a maximum input size because of their need to attend to all tokens in the input. For instance, with Llama 2 your prompts can’t be longer than 2,048 tokens. There are many ongoing efforts on extending this size.
Bertsch et al. (2023) propose Unlimiformer. A long-range Transformer with a virtually unlimited length input.
Unlimiformer “offloads the cross-attention computation to a single k-nearest-neighbor (kNN) index, while the returned kNN distances are the attention dot-product scores”. In other words, it augments LLMs with data retrieval. The context window is dynamically updated at each decoding step given information from a data store.
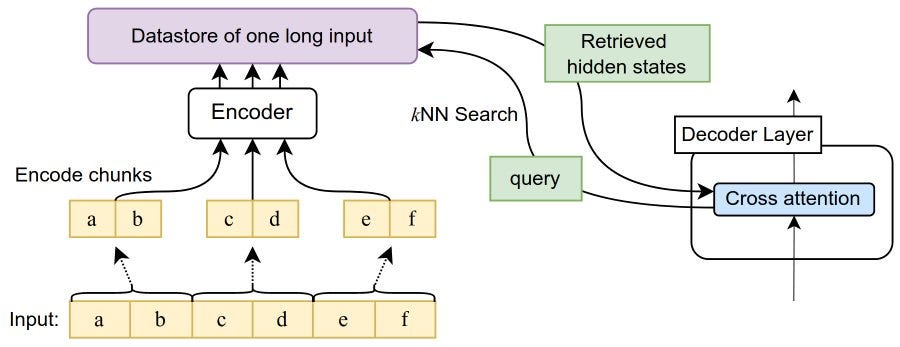
One of the main strengths of this approach is that it is applicable to any encode-decoder model.
The authors did automatic summarization experiments with sequences as long as 500k tokens. They observed better performance than with the original LLMs not wrapped with Unlimiformer.
The approach seems computationally efficient.
Synthesize Instruction Datasets
Li et al. (2023) show in “Self-Alignment with Instruction Backtranslation“ that you can create synthetic instruction datasets with an LLM and use this dataset to improve the same LLM.
The proposed method is very simple.
First, fine-tune an LLM on an existing in-domain instruction dataset. Usually, such a dataset is too small to yield good fine-tuning.
Then, take in-domain documents and label them with an instruction generated by your fine-tuned LLM.
Use the same LLM to score the generated instructions and remove the most spurious instructions according to this score.
Your synthetic instruction dataset is now ready to be used for further fine-tuning the LLM. Iterate until you don’t see any improvement.
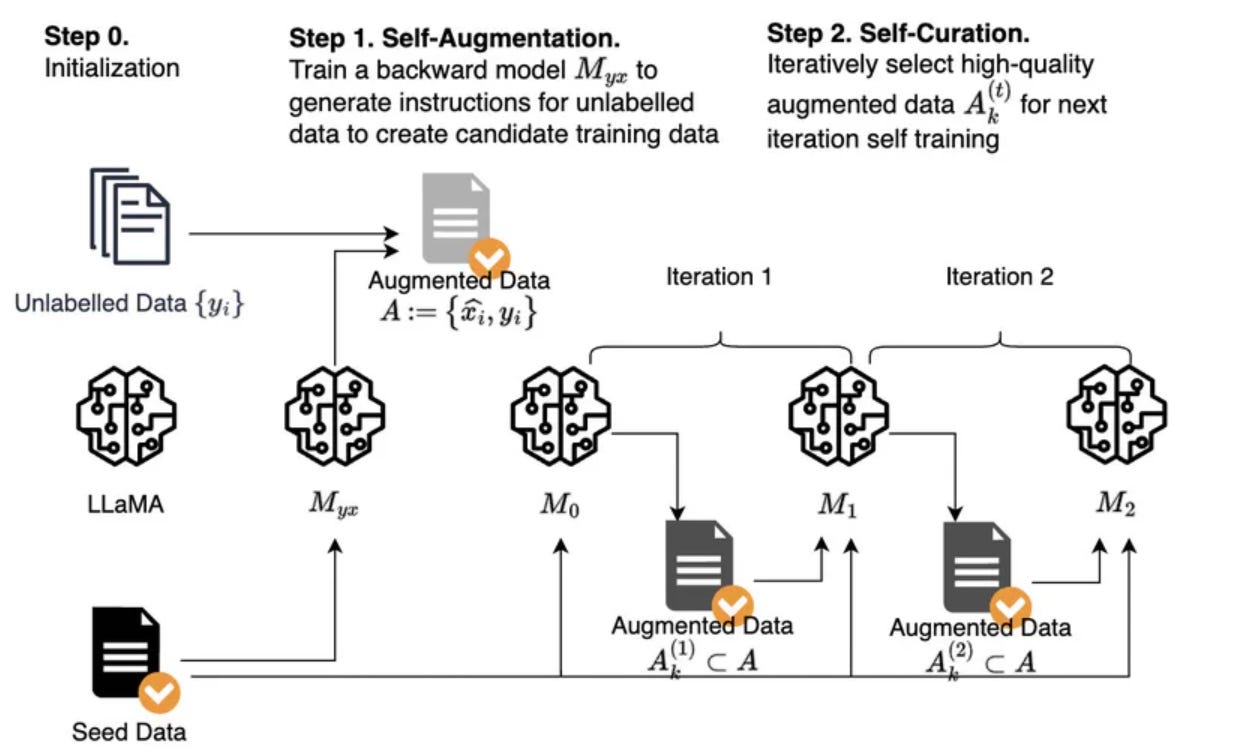
Simple but powerful.
The authors demonstrate significant gains with their self-trained model (Humpack):
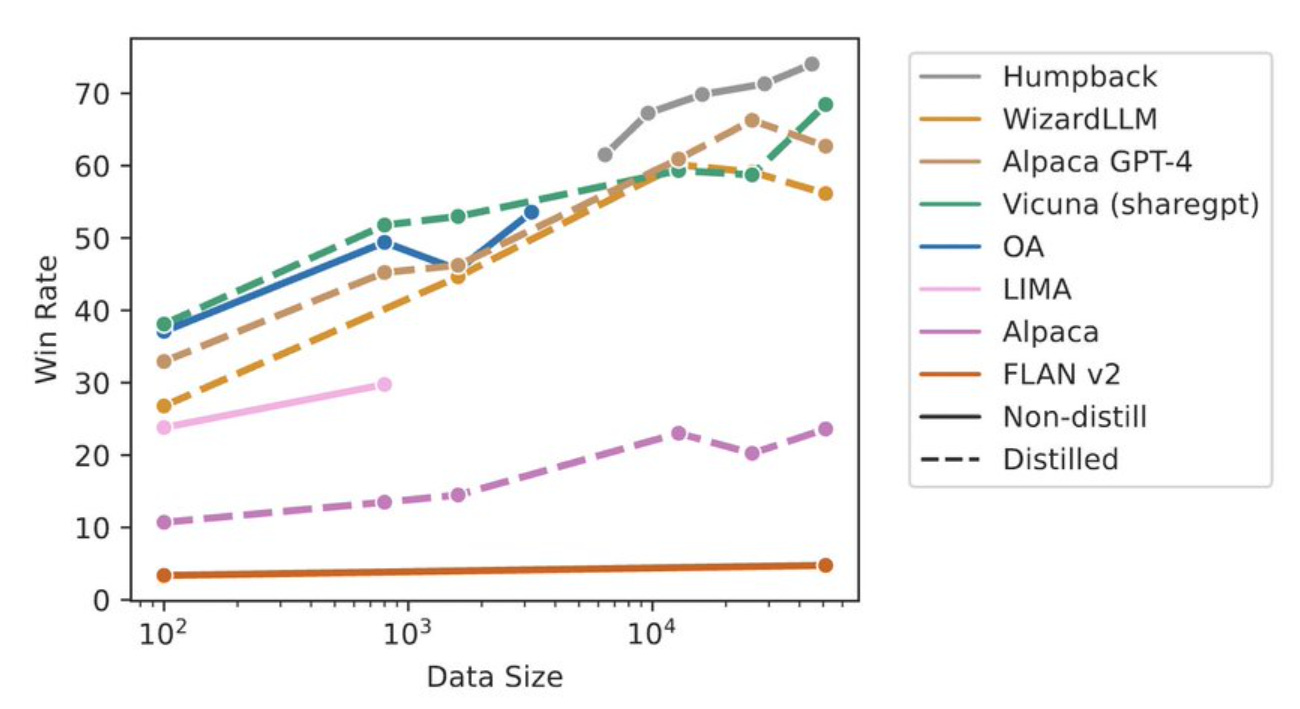
But why this work has “backtranslation“ in its title? Where is the translation step?
The title is somewhat misleading. There isn’t any translation.
Backtranslation is a process that machine translation practitioners use to generate synthetic translation data. It uses a translation system to generate translation and then the generated translation is used to retrain the translation system.
The original backtranslation method has some similarities with what Li et al. (2023) propose, hence the use of “backtranslation“ in the title.
QAmeleon: A Multilingual QA Dataset
Google released QAmeleon a high-quality QA dataset generated with PaLM-540B.
It consists of 47k pairs of question-answer in very diverse languages: Arabic, Bengali, Finnish, Indonesian, Korean, Russian, Swahili, and Telegu. QAmeleon is distributed with a license CC-BY-4.0.
Google mentions that using this dataset for fine-tuning models for QA improves performance:
We use the synthetic data to finetune downstream QA models leading to improved accuracy in comparison to English-only and translation-based baselines.
How is LLaMa.cpp possible?
Large language models can efficiently run on CPU thanks to frameworks like LLaMa.cpp.

But how is it possible? How a 7 billion parameter model can generate 7 tokens/sec on a MacBook?
This is all well explained by Finbarr Timbers in this article:
Warning: This article has a lot of equations.
TL;DR It’s all about memory bandwidth. While GPUs are usually much faster than CPUs, their performance is bounded by the memory bandwidth. During inference, the CPU or GPU, whichever you use, has to transfer data to its computing units. This transfer is the bottleneck. If you take an A100 and compare it with the MacBook M2, the A100 has a memory bandwidth that is only 20 times larger than the M2.
This bottleneck on GPU tends to disappear as you increase your batch size thanks to the much better parallel computing capabilities of GPUs. But if you do inference with a batch size of 1, an M2 would only be 20 times slower than the A100.
Don’t buy expensive GPUs if your target tasks only create tiny batches.
Pad right when you use SFTTrainer
For closing this weekly Kaitchup, a useful tip: pad right when you use TRL’s SFTTrainer.
If you set the padding side of the tokenizer to “left“ and run SFTTtrain, you will get a warning:
/usr/local/lib/python3.10/dist-packages/trl/trainer/sft_trainer.py:207: UserWarning: You passed a tokenizer with `padding_side` not equal to `right` to the SFTTrainer. This might lead to some unexpected behaviour due to overflow issues when training a model in half-precision. You might consider adding `tokenizer.padding_side = 'right'` to your code.
In my previous article about padding, I wrote that the padding side doesn’t matter if you use the UNK token for padding. If you use SFTTrainer, choosing “left“ may lead to overflow issues. Pad right to avoid them.
