

The Weekly Kaitchup #22
The Weekly Kaitchup #22
SPIN - Tricksy - Microsoft's Embeddings


Hi Everyone,
In this edition of The Weekly Kaitchup:
SPIN: Self-play Fine-tuning to Improve LLMs without Additional Data
Tricksy: Fast Inference with Sparsity Aware Offloading
Efficient Text Embeddings with Synthetic Data and Minimal Training Steps
The Kaitchup has now 1,440 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
SPIN: Self-play Fine-tuning to Improve LLMs without Additional Data
Synthetic data generated by LLMs are successfully used to train smaller LLMs. Phi-2 and Zephyr are two very good examples of popular LLMs trained on synthetic data. But these data are additional data, i.e., we need another, better, LLM to generate them.


Can the LLM improve its fine-tuning using synthetic data that it has generated by itself, i.e., without using any additional data or external LLMs?
To answer this question, Chen et al. propose SPIN, a method for self-training LLM:
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
SPIN uses two “player” models. The main player is trained to distinguish LLM responses from human responses by minimizing a specific value. This value reflects the degree of belief that a given response, given a prompt, originates from a human rather than the LLM. The opponent player model seeks to improve the LLM, making its responses indistinguishable from human data for the main player.
Both the main and opponent players are iteratively updated given their respective feedback.
For fine-tuning, SPIN requires only the initial model and the existing supervised fine-tuning dataset, enabling LLM self-improvement. The initial model used by the authors is Zephyr trained without DPO:
SPIN surpasses the performance achieved after DPO with additional preference data.
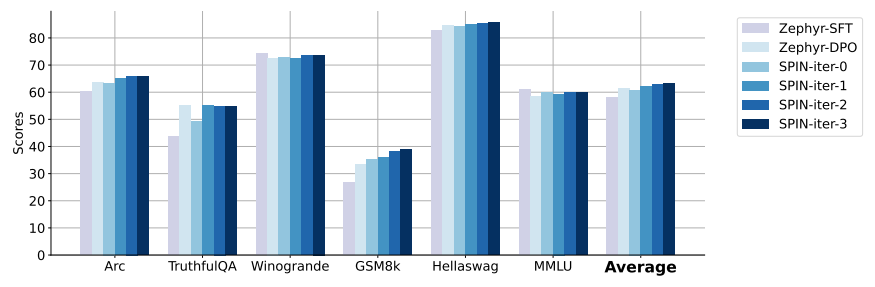

Iterative training is more effective than training for more epochs, with SPIN maintaining performance even with extended training durations.
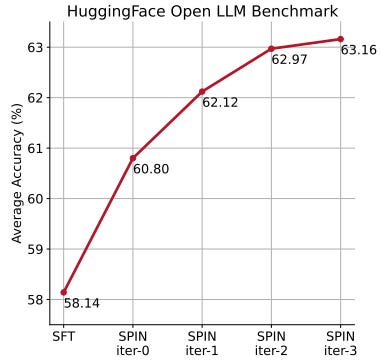
The fact that SPIN outperforms DPO without additional data is quite impressive. The paper is, however, not very clear on how difficult it is to find the right hyperparameters. SPIN and its players have a lot of similarities with GANs (Generative Adversarial Networks) which are well-known to be difficult to train.
Tricksy: Fast Inference with Sparsity Aware Offloading
The MLP layers of large language models exhibit a natural sparsity, with a significant portion of dead neurons having no impact on the output for most inputs. For instance, some layers of OPT-66B have 70% of their neurons that are never activated. Additionally, there is a notable sharing of active neurons among adjacent tokens.
Tricksy aims at exploiting this sparsity to optimize CPU-GPU data transfer. It offloads to the CPU a significant number of parameters to reduce GPU memory usage while preserving a reasonable inference speed.
This approach is much less naive than Accelerate’s device_map offloading.

How does it work?
The framework stores a subset of each MLP layer (around 30%) and full attention layers on the GPU, while the complete MLP layers are stored in CPU RAM. This offloading saves a significant amount of GPU memory. A cache of currently active neuron indices on the GPU is also maintained.
Then, during inference and before each decoder layer's forward pass, the active MLP neurons are predicted based on the attention layer input. During attention computation, the difference between predicted and existing active neuron indices is computed asynchronously on the CPU.
The identified neurons are then copied from CPU RAM to the GPU, and the layer's neuron indices cache is updated. In the MLP computation stage, the newly received neuron differences are concatenated with existing neurons, and the MLP is computed. Neuron buffers are overwritten with the differences, adhering to a first-in-first-out (FIFO) order.
However, note that this approach introduces some approximations. The accuracy of the model might be lower.
Efficient Text Embeddings with Synthetic Data and Minimal Training Steps
Microsoft has achieved a new state-of-the-art (SOTA) for embedding models, a critical component of Retrieval-augmented generation (RAG) systems.
Their key innovation? Using quick and simple training runs with synthetic data. Microsoft has already demonstrated that they master the generation and exploitation of synthetic data with the Phi LLMs, but this is the first time they have exploited synthetic data at such a scale for embedding models.
The traditional approach involves training on general language data and then on a smaller labeled dataset, which is challenging and expensive. Microsoft’s method effectively eliminates the need for this complex multi-stage training.
To experiment with this new approach, Microsoft used Mistral 7B. The model is available here:
You can find more details in this arXiv paper:
Improving Text Embeddings with Large Language Models
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!