

The Weekly Kaitchup #24
The Weekly Kaitchup #24
DeepSeekMoE - KTO is the best - Marlin - Easy data are enough


Hi Everyone,
In this edition of The Weekly Kaitchup:
DeepSeekMoE: MoE with Segmented and Shared Experts
KTO better than IPO and DPO?
Marlin: a 4bitx16bit Linear Kernel for 4x Faster Inference
Are Easy Training Data Enough to Solve Hard Problems?
The Kaitchup is now registering 100+ new subscribers per week. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
DeepSeekMoE: MoE with Segmented and Shared Experts
The mixture of expert (MoE) models are trending.

In this new work, DeepSeek AI proposes two improvements to the mixture of experts:
Expert segmentation: By splitting the expert’s Feedforward Neural Network (FFN) intermediate hidden dimension, this segmentation allows for the activation of more fine-grained experts within a consistent computational cost. This finer segmentation enables a more flexible and adaptable combination of activated experts, facilitating precise learning of diverse knowledge and enhancing specialization at a higher level.
Expert sharing: It involves isolating specific experts to function as shared experts that are consistently activated. This serves the purpose of capturing and consolidating common knowledge across different contexts. By compressing common knowledge into these shared experts, redundancy among other routed experts is reduced. It aims to enhance parameter efficiency.

Using this architecture, they trained DeepSeekMoE 16B which uses only 2.8B parameters during inference. Their evaluation shows that its performance matches the performance of a standard (non-MoE) 7B model trained on the same data, i.e., achieving a 60% reduction in computation during inference.
They have released the code for inference and fine-tuning but not for pre-training a similar model:
The model is on the Hugging Face Hub:
If you are interested in making your own MoE, have a look at this article:

KTO better than IPO and DPO?
I reported in the previous Weekly Kaitchup that Hugging Face was conducting experiments to compare the performance of three different alignment techniques for LLMs:
Direct Preference Optimization (DPO)

Identity Preference Optimization (IPO)

Kahneman-Tversky Optimization (KTO)
They wrote a report to describe their results here:
Preference Tuning LLMs with Direct Preference Optimization Methods
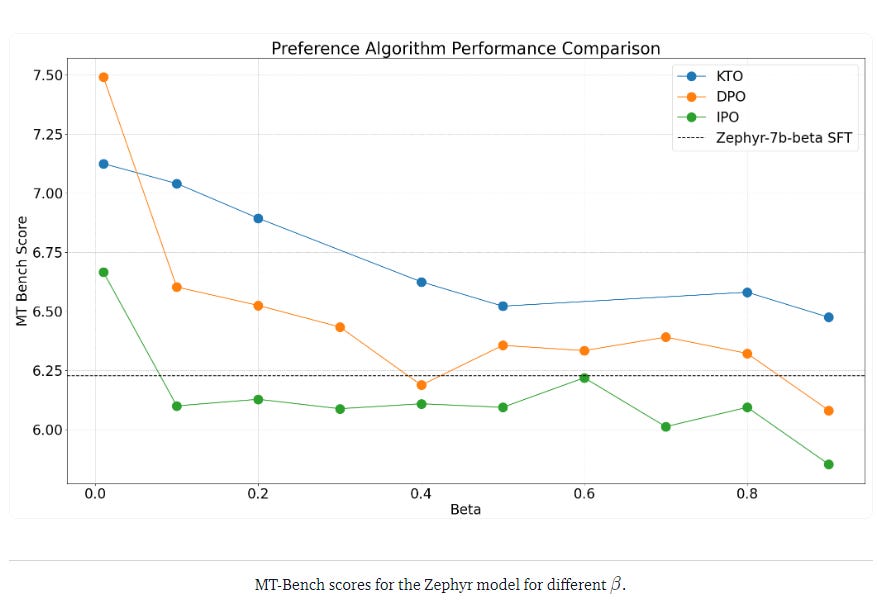
Their observations are surprising to me. While IPO is more theoretically grounded than DPO, and notably much better against overfitting, they found that IPO underperforms both DPO and KTO. KTO is the technique that performs the best.
Another interesting observation is that all these 3 techniques are very sensitive to their Beta hyperparameter. It requires to be carefully selected to obtain optimal results. A low Beta seems to be better.
Marlin: a 4bitx16bit Linear Kernel for 4x Faster Inference
Marlin is a new kernel, compatible with GPTQ models, that significantly speeds up inference with quantized LLMs.

You can get the kernel and have the details on how it works here (it’s clever but complicated):
https://github.com/IST-DASLab/marlin
However, the acceleration tends to become ineffective with larger batch sizes (as expected):

Are Easy Training Data Enough to Solve Hard Problems?
Gathering training data for fine-tuning LLMs is costly and time-consuming. Until now, it has been assumed that, if you want to fine-tune LLMs to solve hard problems, your training data must contain instances of these hard problems. The issue here is that gathering or creating instances of hard problems makes the dataset even more expensive to create.
Hence the research question: Can an LLM learn how to solve hard problems by only learning from simple problems?
If yes, then we wouldn’t need to get hard training data, significantly driving down the cost of the training data.
This work by Hase et al. (2023) shows that LLMs seem to be able, to some extent, to learn how to solve hard problems even when being only trained on simpler problems:
The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
This outcome suggests that easy training data may outperform hard training data (but not the combination of both), given that hard data tends to be more expensive to collect and more prone to noise. These findings hold consistently across different model scales, demonstrating similar effectiveness of easy training data regardless of the model size.

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!
Pity deepseek 16B is weaker than a 13B model