

The Weekly Kaitchup #26
The Weekly Kaitchup #26
TRL's IPO - LLMs with a beacon - OLMo - Mistral 70B?


Hi Everyone,
In this edition of The Weekly Kaitchup:
TRL’s IPO is Fixed!
Extend LLM’s Context with a Beacon
OLMo: Open-source LLMs by AI2
Leaked: A 70B LLM by Mistral AI
The Kaitchup has now 1,847 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
TRL’s IPO is Fixed!
In the Weekly Kaitchup #24, we discussed the performance of different alignment methods evaluated by Hugging Face: KTO, DPO, and IPO.
They concluded that KTO performs the best overall while IPO was underperforming both DPO and KTO despite being more robust to overfitting and more theoretically grounded.
This conclusion was wrong.
The first version of the IPO implementation in TRL was bugged. It is now corrected and the results look much better for IPO:

See the full analysis of the updated results here:
Preference Tuning LLMs with Direct Preference Optimization Methods
If you tried IPO through TRL before and were disappointed by the results, try again!

Note: You may still have to install TRL from the source when reading this article to ensure you are using the fixed version of IPO.
Extend LLM’s Context with a Beacon
A new paper introduced Activation Beacon as a novel approach to extend the context length capabilities of LLMs:
Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon
This method aligns with sparse attention and context compression principles but surpasses previous techniques in extending context and improving long-context generation quality. Additionally, it offers better efficiency in training and inference, along with compatibility with existing LLMs.
Activation Beacon works by condensing raw activations through special tokens, termed beacons, strategically placed within the context. These beacons efficiently compress activations for specific intervals, significantly reducing the size of the data to be processed without sacrificing the model's performance for shorter contexts.
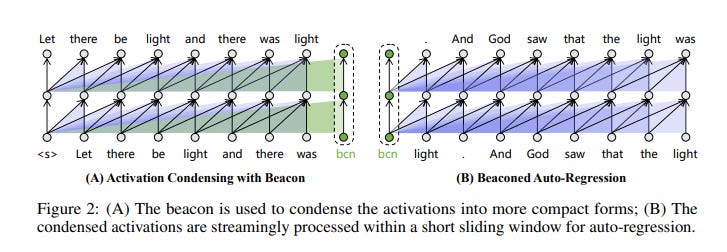
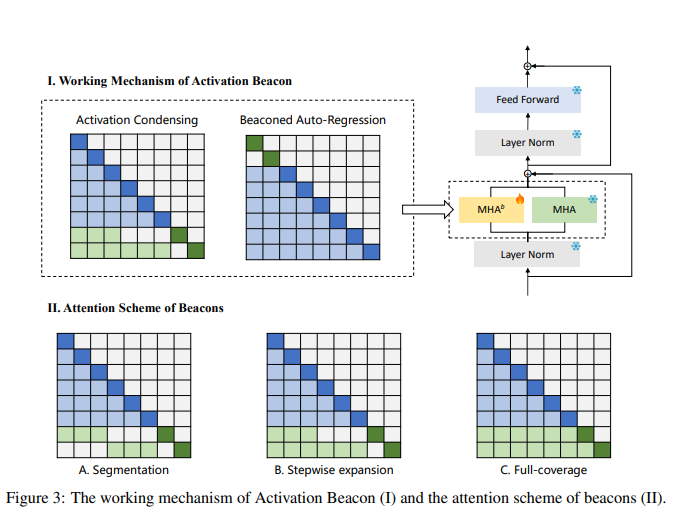
It seems to perform better than the popular StreamingLLM’s attention sinks. The idea of the beacon is similar to the sink, but this approach retains much more information from the context.
An implementation and code examples are available here:
OLMo: Open-source LLMs by AI2
AI2 released two new LLMs:
I think this is the first time that LLMs are released simultaneously with all the resources that were used to create them:
Full training data and the code used to make the data
Training code, logs, and checkpoints
Inference code
Evaluation code
Fine-tuning code
Fine-tuned models
I put in bold in this list all the resources that are usually never published, even by companies claiming that their LLMs are “open”, or worse “open-source”.
AI2 distributes all these resources with an Apache 2.0 license.
However, the OLMo LLMs themselves have nothing special in my opinion. They perform reasonably well on downstream tasks but were only compared by AI2 with older LLMs:

In this table, Mistral 7B is missing. OLMo 7B probably largely underperforms Mistral 7B.
As for OLMo 1B:

TinyLlama is a good baseline but they used an old checkpoint trained on 2.5 trillion tokens. The TinyLlama project released in December a better checkpoint trained on 3 trillion tokens which could be better.
To get more information and resources, check this blog post by AI2.
Leaked: A 70B LLM by Mistral AI
Earlier this week, a mysterious 70B model using the Llama 2 architecture appeared on 4chan. The first evaluations showed extremely good performance (better than GPT-3.5) despite the model being quantized.
Yesterday, Arthur Mensch, one of the co-founders of Mistral AI, revealed that this model had leaked from one of their early-access customers.
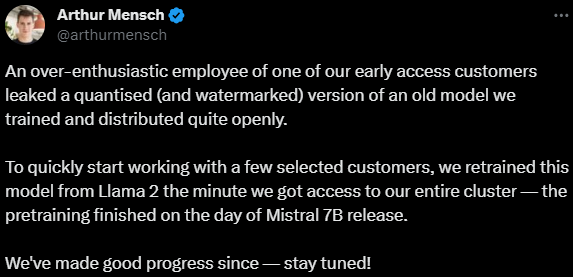
This model is watermarked. It should be easy for Mistral AI to track who leaked it.
LLM watermarking
A watermarked LLM generates patterns of tokens that humans won’t see but that are easily recognizable by the watermarking algorithm.
The model is available here:
Only the quantized GGUF 2, 4, and 5-bit versions are available. You can run them using llama.cpp.
The Salt
In case you missed them, I published two new articles in The Salt this week:

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!