

The Weekly Kaitchup #27
The Weekly Kaitchup #27
ALiBi & FlashAttention 2 - FLAN-T5 again - Cheap Inference by Apple


Hi Everyone,
In this edition of The Weekly Kaitchup:
ALiBi: Now Supported by FlashAttention-2
Is FLAN-T5 Really Better than Llama 2 70B For Summarization Tasks?
Apple’s Recommendations for Cheap Inference from Limited Domain Data
The Kaitchup has now 1,951 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
There is also a 20% discount for group subscriptions (a group of 2 or more):
ALiBi: Now Supported by FlashAttention-2
Transformer models typically use position embedding or rotary embeddings to denote the positions of inputs, which unfortunately can cause these models to overfit to these position indicators. This overfitting hampers the model's ability to handle sequences longer than those seen during training.
ALiBi is a popular method for removing the need for position embedding. Instead, it simply tweaks the attention mechanism of Transformers to introduce a bias, making distant words interact less and closer words interact more. This modification addresses the overfitting and extrapolation issues and enables the model to effectively utilize previously computed keys and queries, enhancing its efficiency and flexibility.
However, computing this bias has a cost that increases quadratically with the sequence length. This bias is computed in the main memory of the GPU before being transferred to the high-speed but tiny SRAM. This transfer constitutes a significant part of the computational cost.
We can alleviate this cost thanks to FlashAttention which now supports ALiBi. It significantly speeds ALiBi up by decreasing by 94% the transfers between HBM and SRAM.

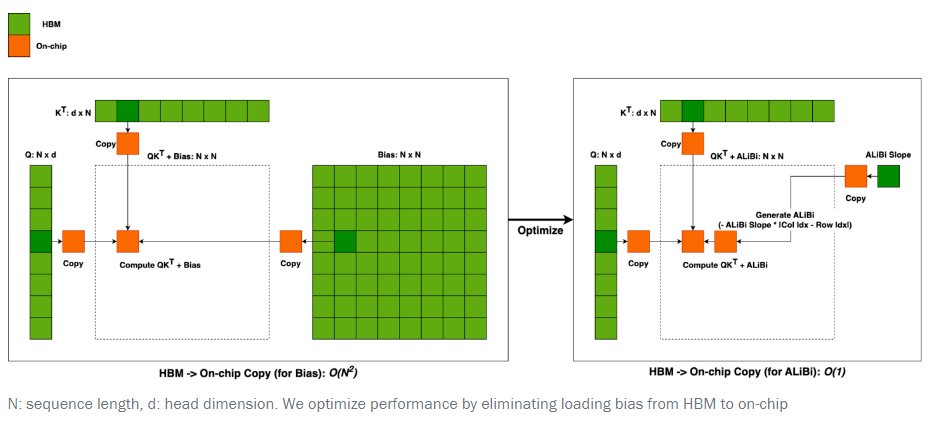
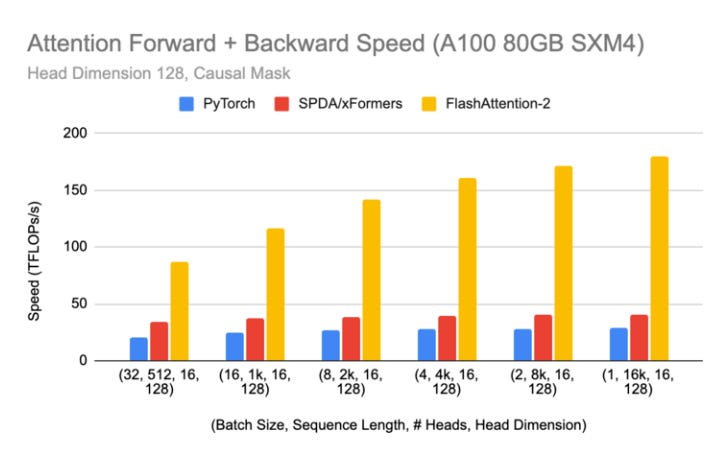
In practice, it makes causal LLMs using ALiBi up to 5x faster.
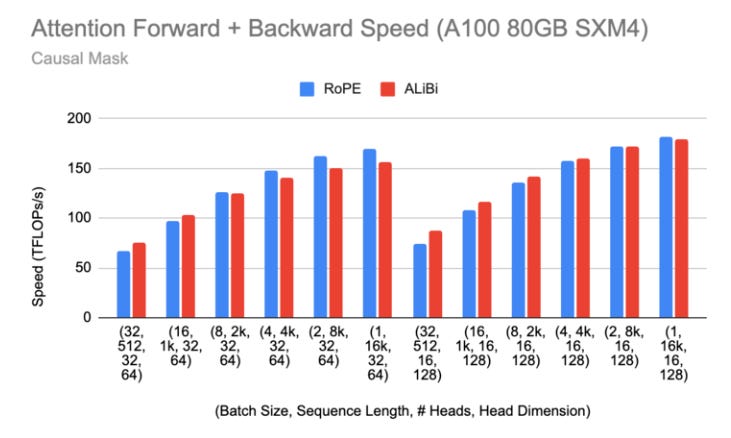
Moreover, it makes ALiBi almost as fast as using the very popular rotary embeddings (RoPE), used by Llama 2 and Mistral 7B.
You can find more information in this blog post:
ALiBi FlashAttention - Speeding up ALiBi by 3-5x with a hardware-efficient implementation
Is FLAN-T5 Really Better than Llama 2 70B For Summarization Tasks?
I saw that this paper was trending on X and other social networks:
Tiny Titans: Can Smaller Large Language Models Punch Above Their
It seems that many misread it. If you only look at the results and don’t carefully read the paper, you might think that FLAN-T5, a 780M parameter model, is better than Llama 2 70B (spelled LLaMA 2 in the paper…) for summarization.
It’s not.
The paper compares FLAN-T5 fine-tuned for summarization against various much larger models not fine-tuned for summarization, i.e., in a zero-shot setting.
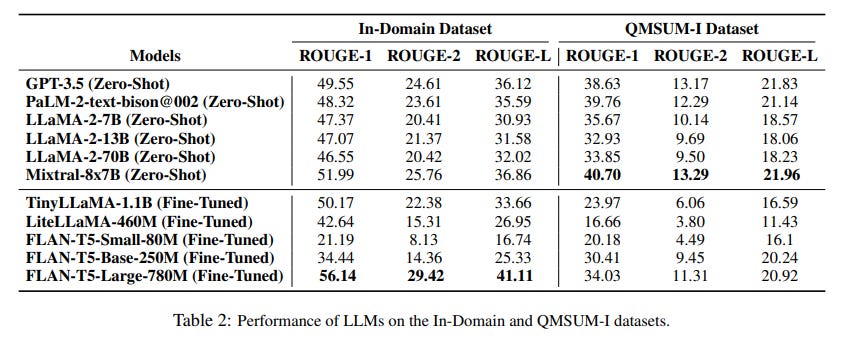
A fine-tuned FLAN-T5 is better, according to ROUGE, than an instruct LLM not fine-tuned for summarization. This is impressive but it doesn’t show how much better the other models would be if they were also fine-tuned for summarization.
Citing this study to write that FLAN-T5 is better than Llama 2 70B is wrong. Moreover, this table only shows scores computed with ROUGE, a largely outdated metric that is often misleading when used to evaluate state-of-the-art LLMs.
The human evaluation performed by the authors shows that zero-shot Llama 2 7B and GPT-3.5 are actually better than FLAN-T5 on the QMSUM-I dataset and that they generate a more coherent summary for the in-domain dataset.
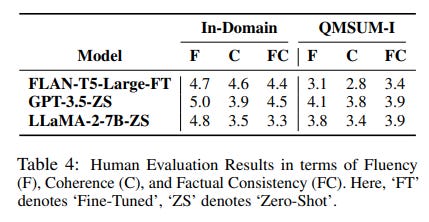
Given these results, I would expect the human evaluation of larger LLMs (not performed by the authors), such as Mixtral-8x7b, to show that they largely outperform FLAN-T5.
Apple’s Recommendations for Cheap Inference from Limited Domain Data
This is an interesting and original study by Apple about the training of small, specialized models using limited domain-specific data:
Specialized Language Models with Cheap Inference from Limited Domain Data
It uses three key elements to maintain low perplexity with limited domain data:
Generic training corpora
Importance sampling
Asymmetric models with fewer parameters at inference than during training, such as mixtures of experts or hyper-networks.
These elements help manage the inference cost and the constraints of limited in-domain training data. They evaluate different strategies using these elements for training with four metrics:
The pretraining cost on a generic dataset, which can be amortized across multiple specializations
The fine-tuning cost specific to each specialized model
The operational cost for running the specialized model, with an emphasis on minimizing parameter count to ease deployment
The size of the specialization training set (which affects decisions on pretraining and specialization
Using these metrics, this study provides practical recommendations for training language models within specific computational constraints, considering the trade-offs between pretraining, specialization, and the operational efficiency of deployed models.
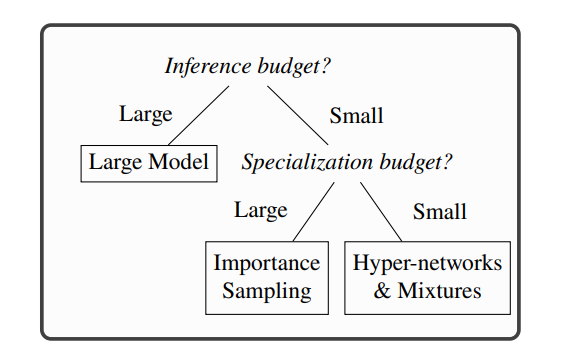
They conclude that when there is a substantial budget available for specialization, using small models that have undergone pretraining through importance sampling is a good choice. This involves pretraining on a broadly sourced corpus that has been selectively sampled via importance sampling techniques.
On the other hand, for scenarios where the specialization budget is more limited, the optimal strategy is to allocate resources towards generic pretraining of hyper-networks and mixtures of experts. These asymmetric models require many parameters during the pretraining phase but can be scaled down to a more compact model for the specialization phase.

The Salt
In case you missed it, I published one new article in The Salt this week:

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!