

The Weekly Kaitchup #38
The Weekly Kaitchup #38
Phi-3 - OpenELM - Llama 3 with QDoRA - FineWeb


Hi Everyone,
In this edition of The Weekly Kaitchup:
Microsoft’s Phi-3: More Parameters and Longer Context than Phi-2
OpenELM: Small Open LLMs by Apple
Llama 3 with QDoRA: A Surprisingly Good Combination
FineWeb: 15T Tokens of High-Quality
The Kaitchup has now 3,170 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (60+) and more than 100 articles.
Microsoft’s Phi-3: The Llama Architecture and More Parameters than Phi-2
Microsoft continues to improve the Phi models. They released Phi-3:
Introducing Phi-3: Redefining what’s possible with SLMs
Currently, only the “mini” instruct versions are available with the support of 4k and 128k context sizes:
Both models have 3.82B parameters. That’s 1.1 billion more than Phi-2.

Microsoft also plans to release versions with 7B and 14B parameters.
They kept the same training recipe with a mix of high-quality synthetic data generated by other LLMs and “web” data. Phi-3 also adopts Llama’s neural architecture which should make Phi-3 much easier to use than Phi-2 since most frameworks already support very well the Llama architecture.
As usual with the Phi models, the benchmark scores look suspiciously good:
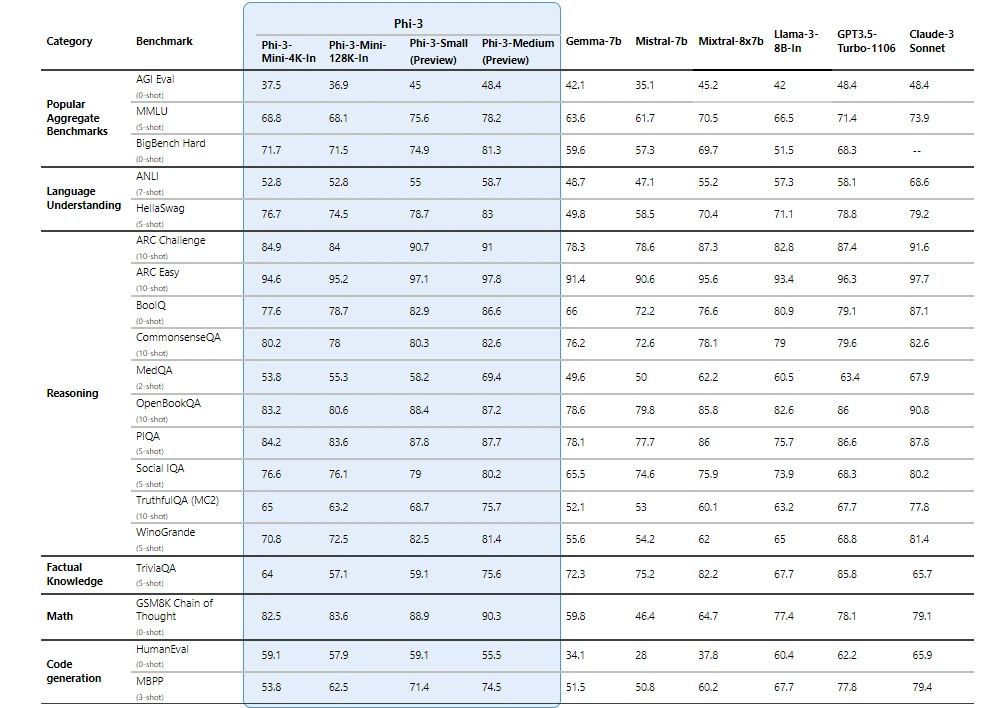
For some benchmarks, Phi-3 mini has better scores than Llama 3 8B. This can be due to some data contamination, i.e., some of the benchmark data might have been in the training data of Phi. We will never know why Phi performs so well since Microsoft never releases the training data.
Nonetheless, the Phi models have always been performing well in numerous applications and because they are small they can run on most configurations.
I’ll review the models and the technical report, probably next week.
OpenELM: Small Open LLMs by Apple
Apple released OpenELM, a family of small LLMs with 270M, 450M, 1.1B (same size as TinyLlama), and 3B (similar size to Phi-2) parameters.
Due to their size, these models don’t perform well on the benchmarks but they can run on devices where other larger LLMs can’t. With OpenELM, Apple is aiming at devices with small memory such as phones, watches, or even smaller than that.
The models were trained on 1.8T tokens from open datasets: RefinedWeb, deduplicated PILE, a subset of RedPajama, and a subset of Dolma v1.6.
Apple published a technical report:
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
The models are available on the Hugging Face Hub:
Hugging Face Collection: OpenELM
Llama 3 with QDoRA: A Surprisingly Good Combination
Jeremy Howard, founder of answer.ai, has posted on X some interesting results of QDoRA fine-tuning for Llama 3 8B:

It appears that fine-tuning Llama 3 8B with QDoRA significantly outperforms QLoRA and closely performs to full fine-tuning. That’s surprising to me as my experiments with DoRA and QDoRA didn’t yield significantly better results than standard QLoRA:


I have no idea why QDoRA would perform better with Llama 3 than with Mistral 7B. I’ll try to reproduce their results with Hugging Face PEFT using the same hyperparameters but with a single GPU (i.e., not using FSDP as they did).
Meanwhile, you can find my tutorial on how to fine-tune Llama 3 with QLoRA, here:

FineWeb: 15T Tokens of High-Quality
Hugging Face released the FineWeb dataset, a carefully cleaned and deduplicated English web data from CommonCrawl:
The dataset contains more than 15T tokens. This is a corpus of this size, but not this one in particular, that has been used to train Llama 3.
Hugging Face validated the quality of the dataset by training LLMs and compared their performance against LLMs trained on other large datasets such as C4, RefineWeb, etc.

According to their observations, FineWeb trains LLMs of better quality.
This is a huge dataset that would nearly occupy 42 TB on your hard drive. If you want to use this dataset, I rather recommend streaming it:
from datasets import load_dataset
dataset = load_dataset('HuggingFaceFW/fineweb', 'default', split='train', streaming=True)Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) I have checked and updated, with a brief description of what I have done.
This week, I have released a new notebook showing and benchmarking AWQ quantization for Llama 3:
#63 Fast and Small Llama 3 with Activation-Aware Quantization (AWQ)
The notebook shows how to quantize and run Llama 3 with AutoAWQ. Rather than writing a new article, I simply updated the article that I wrote last year on AWQ for Llama 2. I kept the examples with Llama 2 and added new ones for Llama 3.

The Salt
The Salt is my other newsletter that takes a more scientific approach. In it, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed Jamba, a new neural architecture using Mamba and Transformer layers. Jamba is as good as transformer models of similar sizes but faster for inference. You will find my review and examples showing how to fine-tune Jamba, here:

This week in the Salt, I also briefly reviewed:
⭐On Speculative Decoding for Multimodal Large Language Models
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!