

The Weekly Kaitchup #49
The Weekly Kaitchup #49
Better Evaluation for Quantized LLMs - Expert-specialized Fine-tuning


The Kaitchup is one year old!
During this first year, the growth of The Kaitchup exceeded all my expectations. As of now, The Kaitchup has 4,297 subscribers:
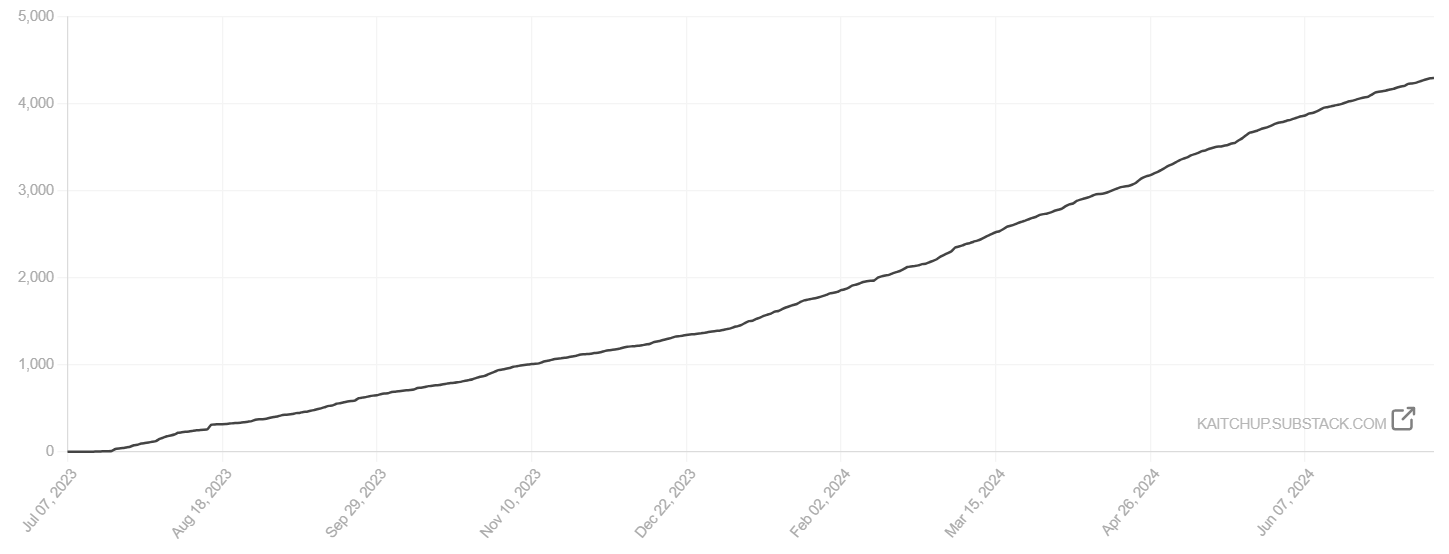
13.5% (580) of The Kaitchup subscribers are paid subscribers!
This was completely unexpected, given that Substack newsletters typically have a conversion rate between 2% and 4% (source: Substack). The Kaitchup has consistently gained new paid subscribers daily for the past six months and is now ranked among the top 40 Substack tech newsletters.
I also noticed that more and more professionals working with AI and companies are subscribing (notably, through group subscriptions).
Thanks to this support, I can invest more time in improving The Kaitchup. I will launch soon a new higher subscription tier proposing additional services, mainly targeting professionals working with AI, but open to everyone. I will provide more details next week.
Finally, as you might have noticed, I’m changing The Kaitchup’s logo. Until now, I was using a free picture but as The Kaitchup is growing, it becomes necessary to use a logo that cannot be used by other AI newsletters.
Now, back to The Weekly Kaitchup:
In this edition:
Are Automatic Metrics Lying? Quantization May Degrade More than Previously Thought
Expert-specialized Fine-tuning by DeepSeek AI
And more: vLLM FP8, logit soft-capping with FlashAttention, and PaliGemma paper
There is still a 25% discount on the yearly subscription to The Kaitchup available until next week. That’s 50% cheaper than the monthly subscription (over a year).
If you are a free subscriber, consider upgrading to paid to access all the notebooks (80+) and more than 100 articles.
AI Notebooks and Articles Published this Week by The Kaitchup

Notebook: #85 Florence 2: Fine-tune a Multimodal Chat Model on Your Computer

Notebook: #86 Train LLM Embedding Models with SimCSE-- Examples with Llama 3
Are Automatic Metrics Lying? Quantization May Degrade More than Previously Thought
Previous work showed that 8-bit and 4-bit quantization greatly reduce the size of LLMs while preserving most of their accuracy.

However, most of the evaluations of quantized models have been conducted for English tasks, assuming that the impact of quantization in other languages would be similar.
It seems that this assumption is wrong.
According to a new study by Cohere, automatic metrics used for the evaluation of quantized LLMs are highly inaccurate, at least for multilingual LLMs:
How Does Quantization Affect Multilingual LLMs?
They have evaluated different quantization methods such as 8-bit quantization, GPTQ, and W8A8-SmoothQuant, for Cohere multilingual models: Command-R, Command-R+, and Aya23.
The main finding is that automatic metrics (such as accuracy on public benchmarks) are highly inaccurate in evaluating quantized multilingual models. While automatic evaluations estimate the performance drop of a quantized model relative to FP16 across tasks to be modest, −0.3% for French and −1.7% for Japanese, human evaluations report significantly larger drops of −16.6% for French and −16.0% for Japanese.

However, note that these results might not be applicable to other LLMs. It definitely requires further investigation as noted in the paper.
Moreover, I think the paper put too much emphasis on “other languages”. Results for English are not shown. I wouldn’t assume that there isn’t a similar performance gap for English in their settings.
Expert-specialized Fine-tuning by DeepSeek AI
DeepSeek AI is known for its huge LLMs exploiting many tiny experts such as DeepSeek-V2. I reviewed it for The Salt:

Expert-specialized fine-tuning (ESFT), recently released by DeepSeek AI, is a new parameter-efficient method for fine-tuning Mixture of Experts (MoE) models.
According to their report, ESFT significantly reduces memory usage by up to 90% and training time by up to 30%, while achieving approximately 98% of full fine-tuning performance. Note: Achieving XX% of full fine-tuning performance is always a bold claim. Finding good hyperparameters for full fine-tuning on a particular dataset is much more costly than with a parameter-efficient method, hence the full fine-tuning baselines are almost always suboptimal.
ESFT involves training only the most relevant experts for specific downstream tasks while keeping the other experts frozen.
The relevance of each expert is assessed using average gate scores and token selection ratios, selecting the best experts for training.
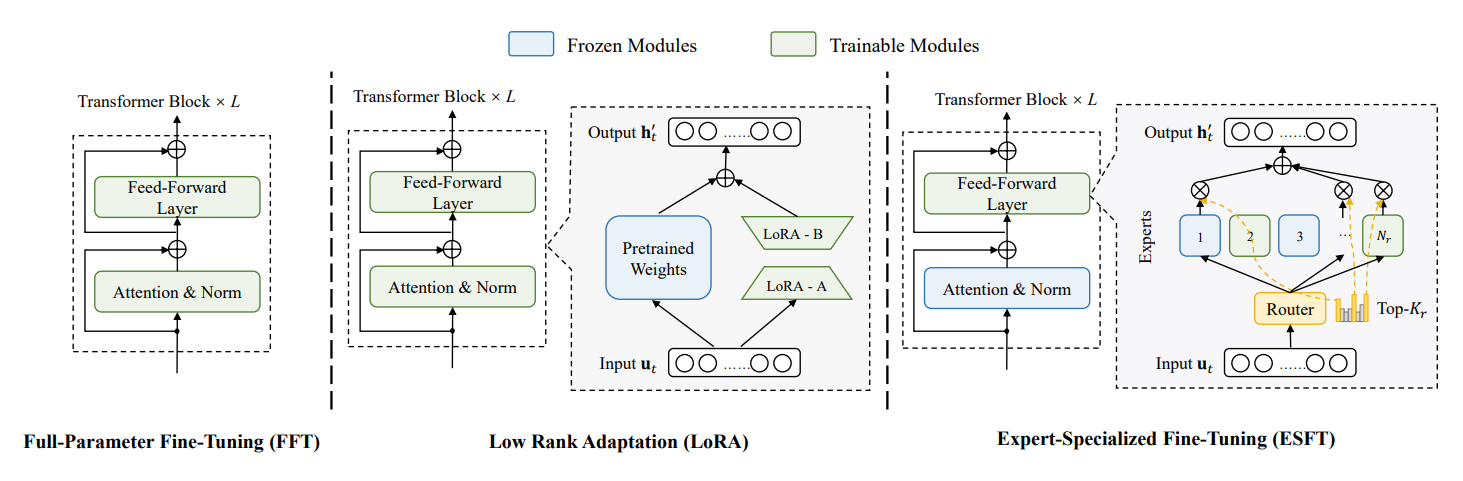
According to their evaluation, ESFT outperforms LoRA by up to 10%, decreases memory requirements from 28.6GB to as low as 2.57GB, and cuts training time from 28.5 minutes to 19.8 minutes. However, ESFT is less effective for coarse-grained MoEs with a limited number of experts, e.g., Mixtral models.
They released code that you can try here:
And More
FP8 for Fast Inference with vLLM
vLLM now supports FP8 quantization. You can load models quantized to 8-bit with vLLM. The main advantages are that inference will be approximately 1.8x faster, with a model twice as small, while preserving 99% of its accuracy.

Logit Soft-capping Compatible with FlashAttention
Gemma 2 are great LLMs by Google. The models use logit soft-capping which was introduced by Gemini 1.5. This soft-capping was not compatible with FlashAttention which meant that we could only use Gemma 2 in the “eager” mode, i.e., consuming a large amount of memory for long sequences.

Soft-capping is now supported by FlashAttention which can thus be used with Gemma 2.
PaliGemma Paper
A quick notification to tell you that Google also published their report describing their work on PaliGemma, a small but very capable VLM:
PaliGemma: A versatile 3B VLM for transfer
PaliGemma is a significant advance in VLMs. While this kind of paper is usually not very informative, I found this one quite insightful in understanding Google’s approach to researching better VLM architectures. The ablation study is also interesting.
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed the report of OpenAI on LLM critics to improve GPT-4 in identifying/explaining errors in code generation.

This week in the Salt, I also reviewed:
⭐Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
Eliminating Position Bias of Language Models: A Mechanistic Approach
⭐UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a discount for group subscriptions):
Have a nice weekend!