

The Weekly Kaitchup #54
The Weekly Kaitchup #54
Llama 3.1 4B Minitron - First Fine-tuned Llama 3 405B - Falcon Mamba 7B


Hi Everyone,
In this edition of The Weekly Kaitchup:
Llama 3.1 4B with NVIDIA Minitron
The First Fine-tuned Llama 3 405B
Falcon Mamba 7B: A Good SSM (attention-free) Model
If you are a free subscriber, consider upgrading to paid to access all the notebooks (90+) and more than 100 articles.
If you are looking for custom AI notebooks, priority support, or professional LLM services, have a look at The Kaitchup Pro:
AI Notebooks and Articles Published this Week by The Kaitchup

Notebook: #94 Quantize and Evaluate Llama 3.1 Instruct with BitsandBytes, AWQ, GPTQ, and AutoRound

Notebook: #95 Fine-tuning Base LLMs vs. Fine-tuning their Instruct Version
Llama 3.1 4B with NVIDIA Minitron
Two weeks ago, I reviewed Minitron in the Weekly Salt (free article):

NVIDIA's method reduces the size of LLMs by pruning attention heads and shrinking both the hidden size and MLP intermediate dimension (width pruning). While Minitron can also prune layers (depth pruning), NVIDIA confirmed that this approach is more detrimental to the model's performance.
NVIDIA applied their recipe to Llama 3.1 8B to create a 4B version.
To obtain this 4B parameter model, they pruned the MLP intermediate dimension from 14336 to 9216 and the hidden size from 4096 to 3072.
Then, they trained the resulting model with knowledge distillation, using Llama 3.1 8B as the teacher.

They released the model here.
They also benchmarked this 4B model:
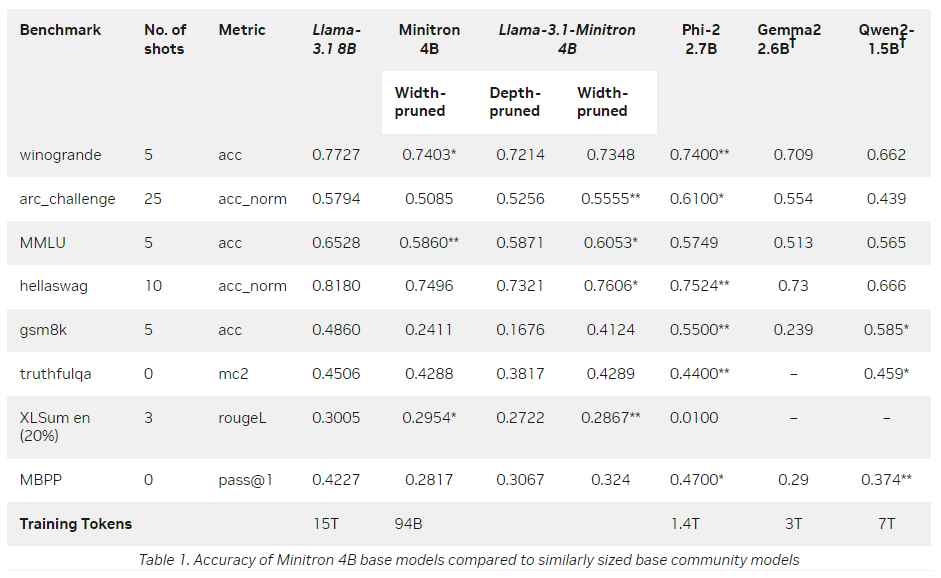
Note: Ignore the results for Phi-2, Gemma 2, and Qwen2. They are not comparable (computed differently) and shouldn’t be put in the same table.
It performs reasonably well for a 4B model. However, they didn’t compare it with:
Models of similar size (Phi-3 would have been a good baseline)
Quantized versions of Llama 3.1 8B.
State-of-the-art 4-bit quantization techniques like HQQ and AutoRound can retain up to 99% of a model’s accuracy. However, because these methods do not quantize embedding parameters, they result in slightly larger models compared to this 4B model. When weighing the costs, quantization proves to be a significantly more affordable alternative for model compression than Minitron, which involves hyperparameter tuning and model retraining.
Despite this, Minitron is highly impressive, demonstrating that even a heavily pruned model can perform well with knowledge distillation. It paves the way for new research opportunities aimed at reducing the size of LLMs.
The First Fine-tuned Llama 3 405B
Fine-tuning Llama 3 405B is extremely costly. Even with optimizations such as gradient checkpointing and mixed-precision training, we still need 100+ GPUs with 80 GB of VRAM.
Because no single GPU can fully load this model, we need to distribute it across multiple GPUs using tools like DeepSpeed or FSDP.

Nous Research, in collaboration with LambdaLabs, released the first fine-tuned version of Llama 3.1 405B:
I recommend reading their technical report to understand how they did it:
They used FSDP across 128 H100 GPUs distributed over 16 HGX nodes. With a total training batch size of 128, each GPU could only handle a single sequence. They also had to cap sequences at 8,192 tokens, downgrading Llama 3.1’s ability to process very long contexts. Note: The Llama 3.1 models released by Meta have been fine-tuned to accurately process sequences of up to 128k tokens.
They fine-tuned the model for 2086 GPU hours. Looking at LambdaLabs’ pricing, this would have cost $9,300, without including hyperparameter search, debugging, and validation.
Falcon Mamba 7B: A Good SSM (attention-free) Model
The Technology Innovation Institute (TII) in Abu Dhabi has released the first state-space model (SSM) version of Falcon:
Unlike Transformers, SSMs don’t use attention mechanisms, resulting in faster and more memory-efficient inference. While the attention computation in Transformers scales quadratically—making generation increasingly costly with each new token—the inference cost for SSMs remains constant regardless of the number of tokens in the context.
SSMs are now well-supported by deep learning frameworks, and with Hugging Face Transformers, they can be quantized to run efficiently on both GPUs and CPUs.
Despite their potential, SSMs haven't yet been trained to a level where they can compete with leading LLMs from Google (Gemma), Microsoft (Phi), or Meta (Llama). However, with the Falcon Mamba 7B, trained on 5.5 trillion tokens, TII is closing the gap with Transformer models.
They published the following benchmark scores:
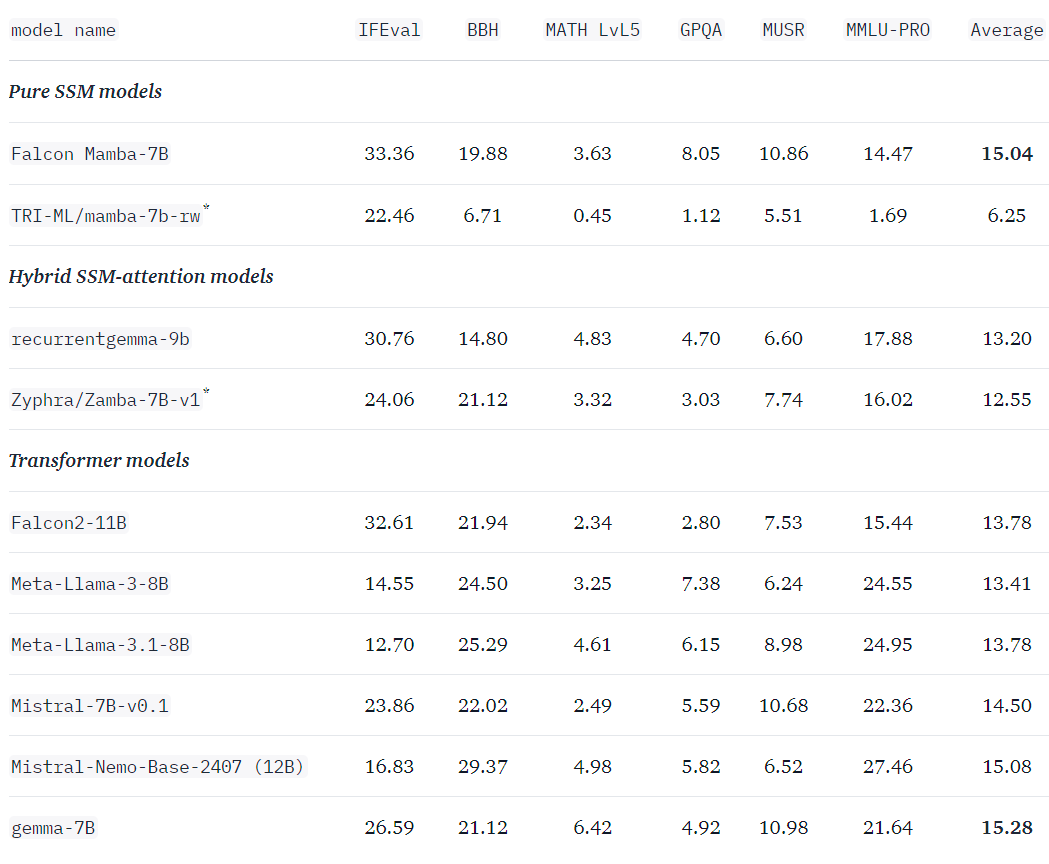
It has better scores than all the other LLMs of similar size, except Gemma 7B.
In their evaluation, they include other SSM models and hybrid SSM/Transformers models but they didn’t consider including RWKV which is another attention-free architecture.
I think Falcon Mamba 7B can be a cost-effective alternative to transformer models of similar size, for costly inference tasks involving long contexts.
If you are interested in knowing more about these attention-free models, I wrote about them in The Salt:


GPU Cost Tracker
This section keeps track, week after week, of the cost of GPUs. It only covers consumer GPUs, from middle-end, e.g., RTX 4060, to high-end, e.g., RTX 4090.
While consumer GPUs have much less memory than GPUs dedicated to AI, they are more cost-effective, by far, for inference with small batches and fine-tuning LLMs with up to ~35B parameters using PEFT methods.

To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
RTX 4090 (24 GB): PNY GeForce RTX™ 4090 24GB VERTO™ (Changed for a cheaper model: $1,729.00 (-$9.99); last week: $1,738.99,)
RTX 4080 SUPER (16 GB): ZOTAC GAMING GeForce RTX 4080 SUPER Trinity Black Edition ($1,027.19 (-$2.8); last week: $1,029.99)
RTX 4070 Ti SUPER (16 GB): ZOTAC GAMING GeForce RTX 4070 Ti SUPER Trinity Black Edition ($799.9, same price as last week)
RTX 4060 Ti (16 GB): PNY GeForce RTX™ 4060 Ti 16GB XLR8 ($459.99, same price as last week)
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) and articles I have checked and updated, with a brief description of what I have done.
Hugging Face Transformers removed the default chat template. Now, if you run “tokenizer.apply_chat_template” it will trigger an error if the model’s tokenizer doesn’t have a chat template.
If the tokenizer doesn’t have one, you can use this:
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"It will work for any model but the special tokens (e.g. <|im_end|>) will be tokenized and won’t be removed after detokenization. You will have to add some custom code to remove them so that they are not seen by your users.
To learn how to create and modify a chat template, have a look at this article:

I started to add this default template to The Kaitchup’s notebooks.
SmolLM supports it and uses the same special tokens used by the template.

Notebook: #93 Fine-tune SmolLM 135M and 370M with Distilled DPO
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week, I reviewed:
⭐Self-Taught Evaluators
Transformer Explainer: Interactive Learning of Text-Generative Models

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!