

The Weekly Kaitchup #6
The Weekly Kaitchup #6
phi-1.5, an LLM full of surprises - Many dead neurons in LLMs - Reduce your benchmarking costs - DeciLM: a very fast LLM


Hi Everyone,
In The Weekly Kaitchup, I briefly comment on recent scientific papers, new frameworks, tips, open models/datasets, etc. for affordable and computationally efficient AI.
In this edition, we will see:
phi-1.5: new LLMs by Microsoft that are suspiciously good on public benchmarks
A new study showing that some layers in LLMs have up to 70% of dead (useless) neurons
A new method to efficiently benchmark LLM
DeciLM: LLMs with a variable grouped-query attention
The Kaitchup has now 512 subscribers. Thanks a lot for your support!
phi-1.5: Is it too good to be true?
Microsoft released phi-1.5 (Li et al., 2023): A 1.3 billion parameter LLM that seems to perform better than larger LLMs, such as Llama 2 7B, on public benchmarks.
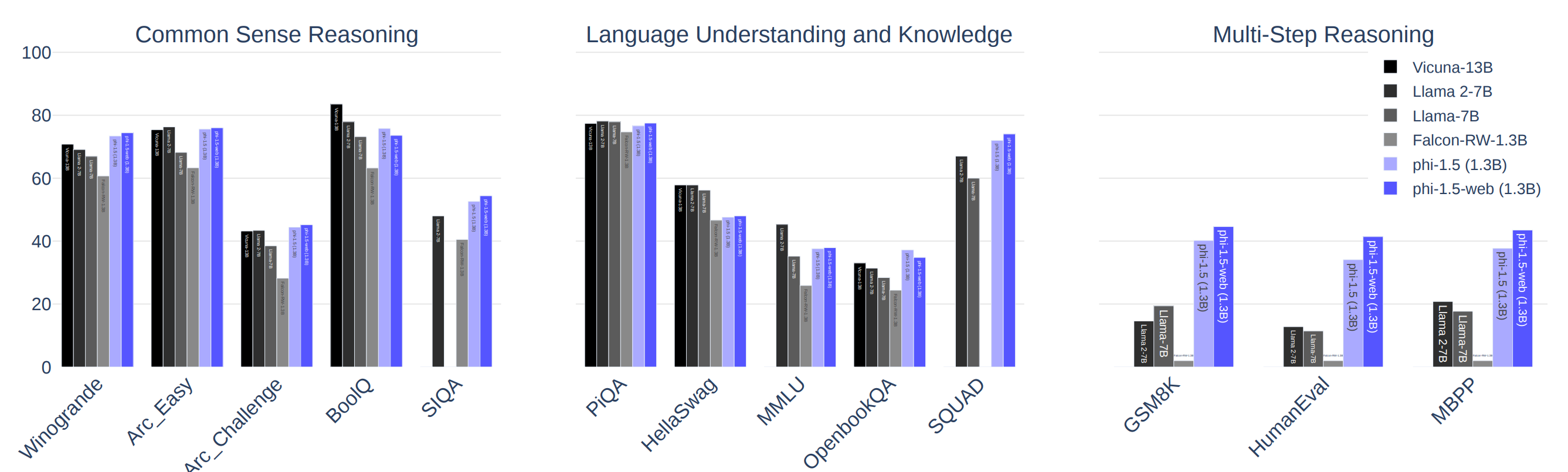
There are two versions of phi-1.5:
microsoft/phi-1_5: Exclusively trained on books (only 30B tokens!).
phi-1.5-web (not released): Training data of phi-1.5 augmented with a carefully curated dataset crawled from the Internet.
Microsoft claims that the data is so high quality that they didn’t need to perform RLHF.
The models are only pre-trained, i.e., not fine-tuned on instruction datasets. As you can see in the results (illustration above), the phi models are already very good for many different tasks.
Since the models are small and the training data is also small, many in the research community found these results suspicious. We can’t explain why the phi-1.5 models are so good on these benchmarks.
On X (ex-Twitter) researchers claimed that they found evidence of data contamination, i.e., phi-1.5 may have been trained on the benchmarks. For instance, Susan Zhang showed that phi-1.5 may have memorized evaluation examples of the benchmarks.
Microsoft didn’t release the training data, so we can’t confirm or reject data contamination.
At least, we can all agree that the results presented by Microsoft are very surprising.
My opinion: With phi-1.5, what matters is that the model is small and good enough to be useful. I’m not sure why we continue to benchmark LLMs on publicly available datasets when we know that there is a high risk of data contamination. These evaluations are more often questionable than insightful.
Many neurons in LLMs are dead
Another interesting study by Voita et al. (2023) analyzing the role of neurons in LLMs:
Neurons in Large Language Models: Dead, N-gram, Positional
One of the most interesting findings of this study is that as the LLMs get bigger they also have a larger proportion of dead neurons, i.e., neurons that are never activated during inference.
For instance, they have found that some layers of OPT-66B have 70% of their neurons that are never activated.
It opens new research directions. We could find ways to eliminate the dead neurons to reduce the model size or find ways to make them useful and get better LLMs.
A more accessible version of this study is available here.
Reduce benchmarking costs with Flash-HELM
Imagine that you have several LLMs that you want to benchmark. This benchmarking could easily cost thousands of dollars, or more if you want to benchmark proprietary models only available through some APIs.
Instead of evaluating all the models on the entire benchmark, Perlitz et al. (2023) propose Flash-HELM to tackle benchmarking tasks as tournaments.
If a model poorly performs on a subsample of the benchmark, it doesn’t qualify for the next evaluation round on other subsamples. You can see it as an approximation of a full benchmarking of all the models.
In practice, this approximation is very efficient if you have models in your list that are clearly better or worse than other models, i.e., models that you can quickly disqualify or qualify based on a few evaluation samples.
Evaluation costs can be drastically reduced as shown by the authors of Flash-HELM:

DeciLM 6B: 15x faster than Llama 2
Deci released new 5.7B parameter LLMs designed to be significantly faster than other models of a similar size:
DeciLM 6B: A model pre-trained on a subset of the SlimPajamas dataset
DeciLM 6B instruct: DeciLM 6B further fine-tuned on a subset of OpenOrca, an instruction dataset.
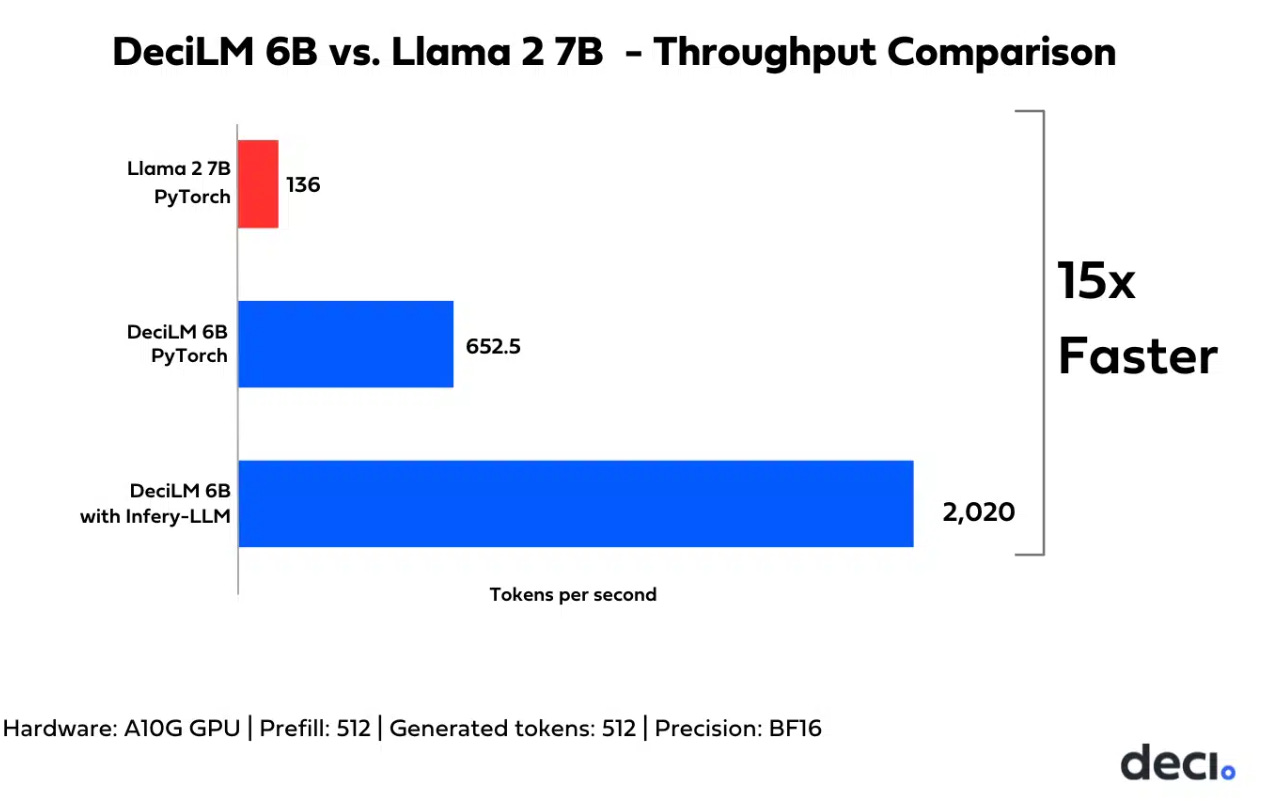
DeciLM models are up to 15 times faster than Llama 2 for inference. It’s also faster than Llama 2 7B with vLLM.

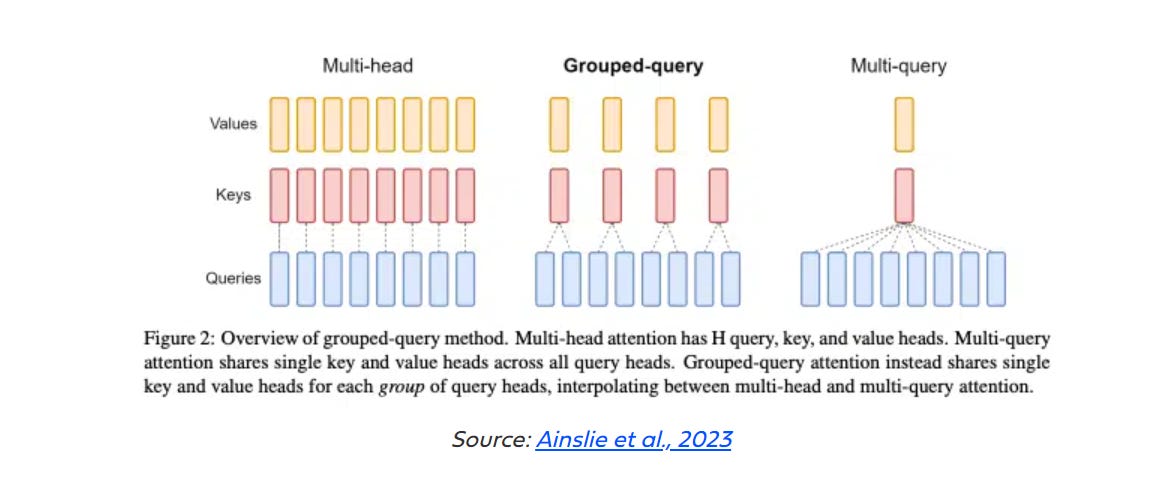
To achieve this speed, the models exploit Grouped-Query Attention (GQA) which significantly speeds up the computation of attention.
The models have this architecture:
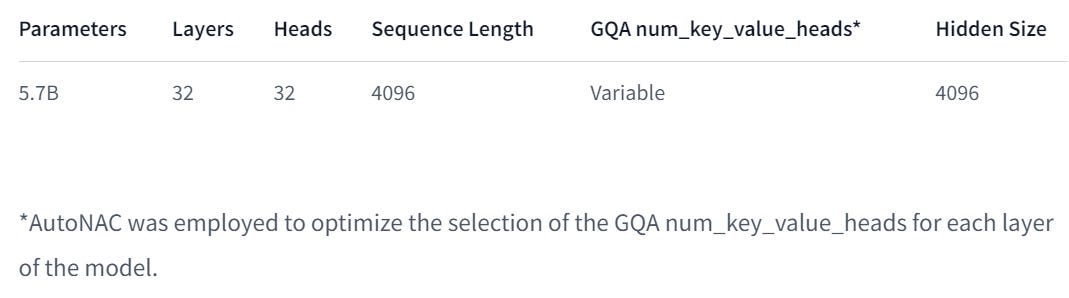
“AutoNAC” is a Deci algorithm that searches for the optimal neural architecture. This is their main innovation: While previous work used the same number of GQA’s groups for each layer, Deci made this number of groups variable.
On public benchmarks, the models seem to perform between Llama 2 7B and Falcon 7B:
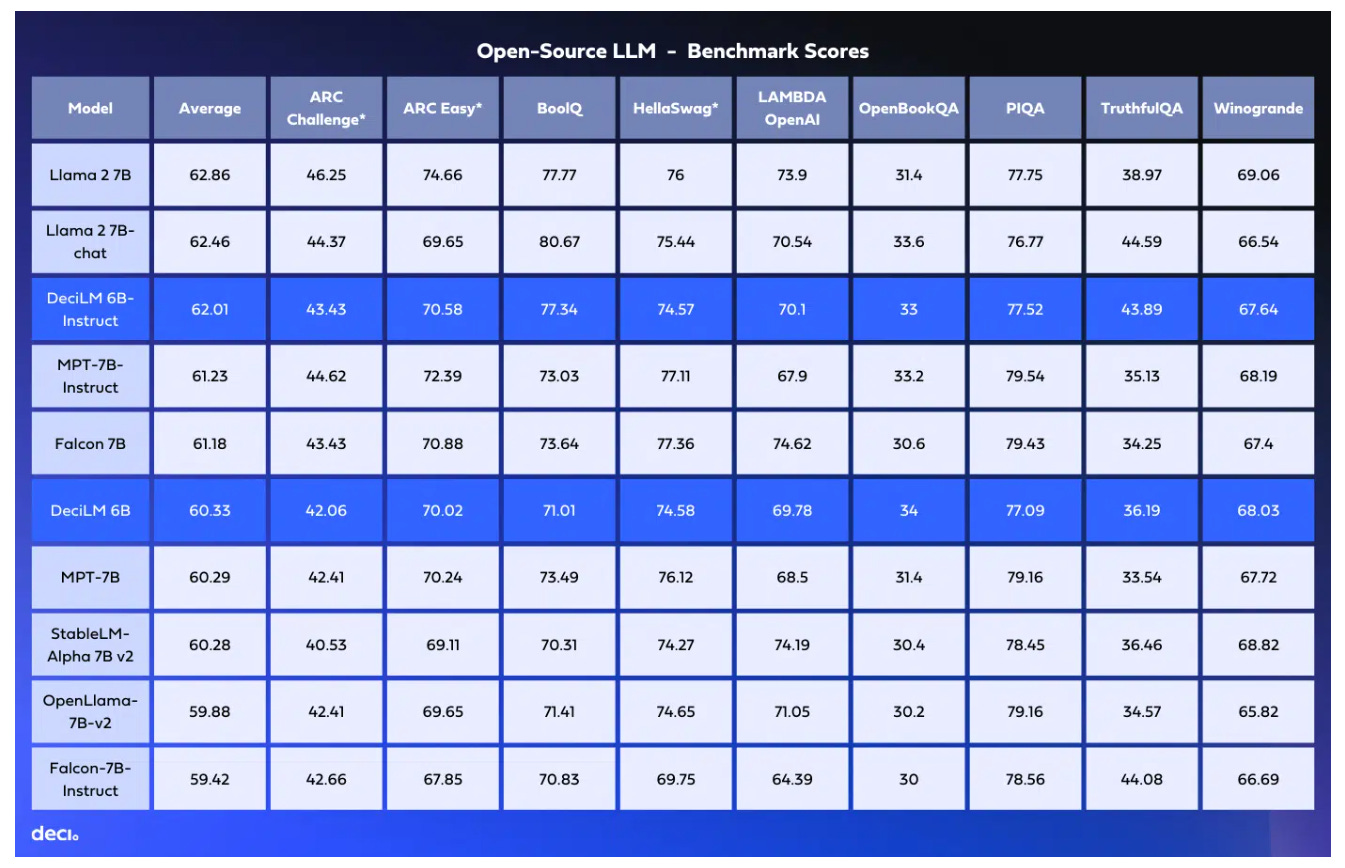
I recommend reading their blog post for more details on the DeciLM models and the variable GQA.
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!