

Watch Out For Your Beam Search Hyperparameters
Watch Out For Your Beam Search Hyperparameters
The default values are never the best


When developing applications using neural models, it is common to try different hyperparameters for training the models.
For instance, the learning rate, the learning schedule, and the dropout rates are important hyperparameters that have a significant impact on the learning curve of your models.
What is much less common is the search for the best decoding hyperparameters. If you read a deep learning tutorial or a scientific paper tackling natural language processing applications, there is a high chance that the hyperparameters used for inference are not even mentioned.
Most authors, including myself, do not bother searching for the best decoding hyperparameters and use default ones.
Yet, these hyperparameters can actually have a significant impact on the results, and whatever the decoding algorithm you are using there are always some hyperparameters that should be fine-tuned to obtain better results.
In this blog article, I show the impact of decoding hyperparameters with simple Python examples and a machine translation application. I focus on beam search since this is by far the most popular decoding algorithm and two particular hyperparameters.
Framework and Requirements
To demonstrate the effect and importance of each hyperparameter, I will show some examples produced using the Hugging Face Transformers package, in Python.
To install this package, run in your terminal (I recommend doing it in a separate conda environment) the following command:
pip install transformersI will use GPT-2 (MIT license) to generate simple sentences.
I will also run other examples in machine translation using Marian (MIT license). I installed it on Ubuntu 20.04, following the official instructions.
Beam Size and Length Penalty
Beam search is probably the most popular decoding algorithm for language generation tasks.
It keeps at each time step, i.e., for each new token generated, the k most probable hypotheses, according to the model used for inference, and the remaining ones are discarded.
Finally, at the end of the decoding, the hypothesis with the highest probability will be the output.
k usually called the “beam size”, is a very important hyperparameter.
With a higher k, you get a more probable hypothesis. Note that when k=1, we talk about “greedy search” since we only keep the most probable hypothesis at each time step.
By default, in most applications, k is arbitrarily set between 1 and 10. Values that may seem very low.
There are two main reasons for this:
Increasing k increases the decoding time and the memory requirements. In other words, it gets more costly.
Higher k may yield more probable but worse results. This is mainly, but not only, due to the length of the hypotheses. Longer hypotheses tend to have lower probability, so beam search will tend to promote shorter hypotheses that may be more unlikely for some applications.
The first point can be straightforwardly fixed by performing better batch decoding and investing in better hardware.
The length bias can be controlled through another hyperparameter that normalizes the probability of a hypothesis by its length (number of tokens) at each time step. There are numerous ways to perform this normalization. One of the most used equations was proposed by Wu et al. (2016):
lp(Y) = (5 + |Y|)α / (5 + 1)αWhere |Y| is the length of the hypothesis and α a hyperparameter usually set between 0.5 and 1.0.
Then, the score lp(Y) is used to modify the probability of the hypothesis to bias the decoding and produce longer or shorter hypotheses given α.
The implementation in Hugging Face transformers might be slightly different, but there is such an α that you can pass as “lengh_penalty” to the generate function, as in the following example (adapted from the Transformers’ documentation):
from transformers import AutoTokenizer, AutoModelForCausalLM
#Download and load the tokenizer and model for gpt2
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
#Prompt that will initiate the inference
prompt = "Today I believe we can finally"
#Encoding the prompt with tokenizer
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
#Generate up to 30 tokens
outputs = model.generate(input_ids, length_penalty=0.5, num_beams=4, max_length=20)
#Decode the output into something readable
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))“num_beams” in this code sample is our other hyperparameter k.
With this code sample, the prompt “Today I believe we can finally”, k=4, and α=0.5, we get:
outputs = model.generate(input_ids, length_penalty=0.5, num_beams=4, max_length=20)Today I believe we can finally get to the point where we can make the world a better place.With k=50 and α=1.0, we get:
outputs = model.generate(input_ids, length_penalty=1.0, num_beams=50, max_length=30)Today I believe we can finally get to where we need to be," he said.\n\n"You can see that the results are not quite the same.
k and α should be fine-tuned independently on your target task, using some development dataset.
Let’s take a concrete example in machine translation to see how to do a simple grid search to find the best hyperparameters and their impact in a real use case.
Experiments with Machine Translation
For these experiments, I use Marian with a machine translation model trained on the TILDE RAPID corpus (CC-BY 4.0) to do French-to-English translation.
I used only the first 100k lines of the dataset for training and the last 6k lines as devtest. I split the devtest into two parts of 3k lines each: the first part is used for validation and the second part is used for evaluation. Note: The RAPID corpus has its sentences ordered alphabetically. My train/devtest split is thus not ideal for a realistic use case. I recommend shuffling the lines of the corpus, preserving the sentence pairs, before splitting the corpus. In this article, I kept the alphabetical order and didn’t shuffle, to make the following experiments more reproducible.
I evaluate the translation quality with the metric COMET (Apache License 2.0).
To search for the best pair of values for k and α with grid search, we have to first define a set of values for each hyperparameter and then try all the possible combinations.
Since here we are searching for decoding hyperparameters, this search is quite fast and straightforward in contrast to searching for training hyperparameters.
The sets of values I chose for this task are as follows:
k: {1,2,4,10,20,50,100}
α: {0.5,0.6,0.7,0.8,1.0,1.1,1.2}
I put in bold the most common values used in machine translation by default. For most natural language generation tasks, these sets of values should be tried, except maybe k=100 which is often unlikely to yield the best results while it is a costly decoding.
We have 7 values for k and 7 values for α. We want to try all the combinations so we have 7*7=49 decodings of the evaluation dataset to do.
We can do that with a simple bash script:
for k in 1 2 4 10 20 50 100 ; do
for a in 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2 ; do
marian-decoder -m model.npz -n $a -b $k -c model.npz.decoder.yml < test.fr > test.en
done;
done;Then for each decoding output, we run COMET to evaluate the translation quality.
With all the results we can draw the following table of COMET scores for each pair of values:
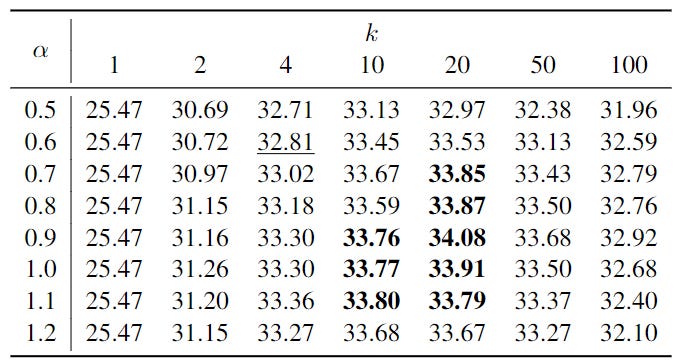
As you can see, the result obtained with the default hyperparameter (underline) is lower than 26 of the other results obtained with other hyperparameter values.
Actually, all the results in bold are statistically significantly better than the default one. Note: In this experiment, I am using the test set to compute the results I showed in the table. In a realistic scenario, these results should be computed on another development/validation set to decide on the pair of values that will be used on the test set, or for real-world applications.
Hence, for your applications, it is definitely worth fine-tuning the decoding hyperparameters to obtain better results at the cost of a very small engineering effort.
Conclusion
In this article, we only played with two hyperparameters of beam search. Many more should be fine-tuned.
Other decoding algorithms such as temperature and nucleus sampling have hyperparameters that you may want to look at instead of using default ones.
Obviously, as we increase the number of hyperparameters to fine-tune, the grid search becomes more costly. Only your experience and experiments with your application will tell you whether it is worth fine-tuning a particular hyperparameter, and which values are more likely to yield satisfying results.